
Lenteur d’une appli Web sur une JVM IBM
Sujet intéressant, les problèmes en production sont quand même pour beaucoup des casse-têtes. Effectivement c’est bien vrai, les problèmes en production sont difficiles à résoudre. Il y a bien une partie technique souvent absconse, mais ce n’est pas un travail en solitaire, c’est un travail d’équipe. L’organisation dans la boite favorise ou freine cette opportunité de résoudre un problème à travers les différentes équipe impliquées. Dans ce billet je vous fait un petit retour d’expérience sur un problème de lenteur sur une application web genre “CRUD” sur une JVM IBM.
Le contexte
“The context is King” disait Andy Hunt dans son livre Pragmatic Learning and Thinking. Alors brève introduction au contexte du problème.
- Application assez simple qui permet de rechercher, consulter, créer, modifier des données différentes issues du domaine métier.
- L’application tourne sur un WebSphere.
- WebSphere tourne sur une JVM IBM. Ah là ça sent la pêche aux informations, n’ayant jamais travaillé sur cette JVM, et pas de bol non plus la JVM IBM sur Windows n’est pas accessible gratuitement depuis le site de IBM.
- L’ensemble tourne sur une machine AIX.
- L’entreprise utilise l’outils Introscope qui permet d’avoir plein de métriques.
Le problème
Les utilisateurs ressentent des lenteurs, voire des freezes. L’outil INSC identifie ces threads en Stalled, et permet de donner des métriques sur les temps d’attentes et de réponses de certains éléments du systèmes, les ingénieurs systèmes utilisent abondamment cet outils. Bref, les temps de réponses vont de quelques dizaines de secondes à plusieurs minutes.
Il y a définitivement un problème. Forcément quand on a un super outils comme INSC qui a plein de métriques, on se balade dedans pour essayer de trouver le problème. Malheureusement un seul thread dump pour voir ce qu’il se passe dans les threads ne suffit pas. Le thread dump révèle que la plupart des threads sont à l’état “Waiting On Condition”. Le super outils INSC indique un usage de la heap, il indique aussi que certaines requêtes SQL sont très très longues, il indique les sessions web ouvertes une petite trentaine, pas de quoi fouetter un chat. Et pourtant il y aurait du CPU assez fortement utilisé, vu depuis Introscope.
Mais voilà l’analyse tourne un peu autour du pot. Pourquoi ces threads sont-elles bloquées? Pourquoi les requêtes SQL sont-elles aussi longues?!
Le problème dans l’analyse
Récapitulons, dans cette situation les métriques de Introscope ont été regardées, et on a un seul thread dump.
Introscope malgré ces métriques ne dit pas ou est le problème, il ne dit même pas quel est le type de problème. Les métriques affichées sont pour certaines intéressantes, je pense à l’identification des threads figées, les temps de réponses de certains composants, la consommation mémoire, et l’utilisation du CPU.
Mais pourquoi cet outils n’a pas aidé à trouver le problème, parce qu’il ne mesure pas les bonnes choses. Et il faut en particulier comprendre que quand un système fonctionne mal il y a un effet de corrélation qui s’applique sur un ensemble de variable. Et ce n’est pas avec Introscope qu’on va pouvoir identifier la cause du ralentissement généralisé, ni trouver** une relation de cause-à-effet**.
Pour résoudre un problème, il faut s’équiper avec les bons outils! Il faut aussi regarder les bonnes données, au bon endroit, et au bon moment!
A la poursuite du vrai problème (partie 1)
Bon hop, déjà pour commencer j’écarte pour le moment Introscope. Et j’ai un thread dump … de la JVM de IBM, il va falloir essayer les outils IBM qui permettent de traiter ces informations. Je vais me satisfaire ça pour l’instant.
L’analyse du thread dump
Avec : IBM Thread and Monitor Dump Analyzer for Java
Évidement le format ne correspond pas à celui de Sun, heureusement IBM nous fournit des outils pour analyser ces informations. Direction : http://www.alphaworks.ibm.com/tech/jca.
A l’ouverture un rapport apparait, il commence par ça en rouge :
WARNING Java heap is almost exhausted : 0% free Java heap Please enable verbosegc trace and use IBM Pattern Modeling and Analysis Tool(http://www.alphaworks.ibm.com/tech/pmat) to analyze garbage collection activities. If heapdumps are generated at the same time, please use IBM HeapAnalyzer(http://www.alphaworks.ibm.com/tech/heapanalyzer) to analyze Java heap.
Ok, là c’est assez facile de savoir ou ça va! Mais allons plus loin!
Il y a également :
**Number of Processors : 4**
Java version : J2RE 5.0 **IBM J9** 2.3 AIX ppc64-64 build j9vmap6423-20090707
Java Heap Information
**Maximum Java heap size : 384m**
**Initial Java heap size : 384m**
OK, j’en apprends un peu plus sur la JVM et la machine.
Free Java heap size: 0 bytes
Allocated Java heap size: 402 653 184 bytes
Ok évidement tout s’explique il ne reste plus rien pour allouer dans la Heap.
Tiens dans la ligne de commande je voit que Introscope est un agent de le JVM:
-Xshareclasses:name=webspherev61_%g,groupAccess,nonFatal
-Dibm.websphere.internalClassAccessMode=allow
-Dcom.wily.introscope.agentProfile=/opt/wily/wilyAgent/AvtAgent.profile
-javaagent:/opt/wily/wilyAgent/Agent.jar
C’est intéressant, si la JVM est lente, ca peut vouloir dire que les mesures Introscope sont aussi soumises aux lenteurs de la JVM.
Le rapport est sympa, il donne la répartition de la mémoire de la JVM :
Memory Segment Analysis:
| Memory Type | # of Segments | Used Memory(bytes) | Used Memory(%) | Free Memory(bytes) | Free Memory(%) | Total Memory(bytes) |
|---|---|---|---|---|---|---|
| Internal | 13 | 1 191 740 | 88,4 | 156 452 | 11,6 | 1 348 192 |
| Object (reversed) | 1 | 402 653 184 | 100 | 0 | 0 | 402 653 184 |
| Class | 9 735 | 228 637 344 | 90,96 | 22 724 116 | 9,04 | 251 361 460 |
| JIT Code Cache | 5 | 41 943 040 | 100 | 0 | 0 | 41 943 040 |
| JIT Data Cache | 3 | 17 018 496 | 67,63 | 8 147 328 | 32,37 | 25 165 824 |
| Overall | 9 757 | 691 443 804 | 95,71 | 31 027 896 | 4,29 | 722 471 700 |
Ok, c’était un tableau intéressant, on voit clairement que dans une JVM il n’y a pas que de la Heap (pour ceux qui ne le savait pas), en effet on voit donc les sections suivantes (les passages surlignés viennent de moi, malheureusement l’outil d’IBM ne nous aide pas là dessus) :
- la mémoire interne de la JVM (les objets internes, les structure de thread, et autres objets natifs) : bonne utilisation
- les objets, en une seule section de mémoire, c’est la Heap, et là ben effectivement elle utilisée à 100%.
- les sections des classes, c’est la ou le byte code de vos classes est stocké par la JVM, mais ce n’est pas dans la Heap (chez la JVM de Sun ça correspondrait à la PermGen area), bref là aussi 90% d’utilisation c’est plutôt pas mal.
- JIT Code Cache et JIT Data Cache, c’est là ou la JVM va stocker le code natif qu’elle aura compilée depuis le bytecode, là aussi c’est rempli à 100% mais c’est peut-être normal, après tout la taille totale est plus petite.
On voit aussi que la mémoire accessible dans la Heap est quand même supérieure a ce qui est indiqué dans la ligne de commande, à savoir les 384 MB. Ne connaissant pas la JVM IBM, je ne suis pas certains des raisons induisant ce phénomène.
Mais à 100% d’utilisation, ça sent le GC qui s’excite pour garder ses petits. Mais le rapport est long et n’est pas terminé, il reste des choses à lire.
Thread Status Analysis :
| Status | Number of Threads : 170 | Percentage |
|---|---|---|
| Deadlock | 0 | 0 % |
| Runnable | 12 | 7 % |
| Waiting on Condition | 158 | 93 % |
| Waiting On Monitor | 0 | 0 % |
| Suspended | 0 | 0 % |
| Object.wait() | 0 | 0 % |
| Blocked | 0 | 0 % |
| Parked | 0 | 0 % |
Vous vous souvenez des threads vues en Wait on Condition au tout début, on les retrouve donc ici dans les stats du thread dump. Il y a environ 158 thread qui ne font rien et 12 threads qui travaillent. Alors petite parenthèse, qu’est ce que ça veut dire ce Waiting on Condition. Les raisons peuvent être les suivantes :
Thread.sleep(), en gros on indique simplement à la thread de ne rien faire, mais c’est quand même la JVM qui gère cesleep()Object.wait(), en gros quelque part dans le code un thread est en attente pour qu’une condition se réalise, voire le code en question pour en savoir plus sur la condition. Cette condition peut aussi être une condition interne à la JVM.- La thread est en train de se synchroniser avec une autre, elle doit donc attendre que l’autre thread finisse son job, on verra probablement dans la stack un appel à un
Thread.join(). Unsafe.park, et autres support pour les lock- La thread est blockée par des opérations d’I/O.
Déjà ce n’est pas forcément un problème pour toutes les threads, typiquement on peut s’attendre à voir des threads relatives aux systèmes de cache (ehcache et consorts) qui sont dans ces états. Ensuite il faut comprendre que ce mécanisme implique des conditions internes à la JVM. L’ordonnanceur (scheduler) de la JVM, qui en réalité fait appel au scheduler de l’OS, donne la main à d’autres traitements (java ou pas).
Le prochain tableau du rapport nous indique ou sont (toutes) nos threads, mais pas d’analyse par type de statut. On observe bien certaines des raisons citées plus haut.
Thread Method Analysis :
| Method Name | Number of Threads : 170 | Percentage |
|---|---|---|
| java/lang/Object.wait(Native Method) | 88 | 52 % |
| java/lang/Thread.sleep(Native Method) | 63 | 37% |
| NO JAVA STACK | 6 | 4 % |
| java/net/PlainSocketImpl.socketAccept(Native Method) | 5 | 3 % |
| java/net/SocketInputStream.socketRead0(Native Method) | 3 | 2 % |
| com/ibm/misc/SignalDispatcher.waitForSignal(Native Method) | 1 | 1 % |
| d’autres ligne à 1%… |
Pas mal de thread sont en attente, et beaucoup d’autres dorment. Quelques threads sans stack Java, ce sont des threads qui appartiennent à la JVM.
J’arrête là pour le moment sur le rapport de cet outils IBM, mais ce qu’il faut retenir c’est que le thread dump est utile pour étudier des threads, mais c’est utile sur un laps de temps, avec un seul cliché on ne se rends pas compte réellement du comportement. Et en plus ces données ne sont pas intéressantes pour savoir ce qu’il se passe coté gestion mémoire. Heureusement que J9 (la JVM de Mr IBM) fournit quelques infos, sinon je ne vois pas comment diagnostiquer le problème sans jeter un œil sur les données adéquates, c’est à dire le log du Garbage Collector.
L’analyse du log GC, enfin!
Après l’obtention du fameux log, il faut encore trouver un outil IBM pour analyser le fichier. Les choses deviennent intéressantes. Comme je l’ai déjà dit, les logs sont au format IBM, ça ressemble à du XML. Et pour analyser ces logs rien de mieux que les outils de IBM, non? Google me dit rapidement qu’il me faut donc ce truc Pattern Modeling and Analysis Tool for Java Garbage Collector, à nouveau direction http://www.alphaworks.ibm.com/tech/pmat.
Avec : Pattern Modeling and Analysis Tool for Java Garbage Collector
Un petit graphique pour regarder ce qu’il se passe.
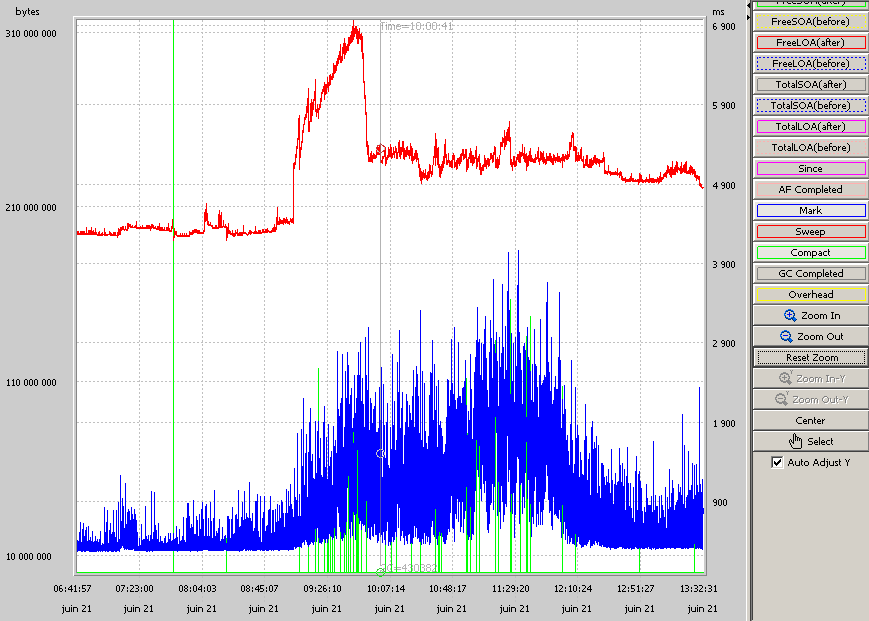
En rouge l’usage de la Heap, en bleu le marquage des objets à virer, et en vert les temps de compression de la mémoire. Effectivement le GC à l’air de bien s’amuser dans la mémoire, et d’être appelé assez souvent.
Bon celà dit je ne suis pas convaincu par l’outil IBM, il manque des informations que j’avais vu en texte dans le log GC ; un évènement GC à cette tête là :
<af type="tenured" id="388571" timestamp="Jun 21 03:01:11 2010" intervalms="228.858">
<minimum requested_bytes="168" />
<time exclusiveaccessms="0.489" />
<tenured freebytes="0" totalbytes="402653184" percent="0" >
<soa freebytes="0" totalbytes="402653184" percent="0" />
<loa freebytes="0" totalbytes="0" percent="0" />
</tenured>
<gc type="global" id="388576" totalid="388576" intervalms="230.720">
<refs_cleared soft="0" threshold="32" weak="76" phantom="0" />
<finalization objectsqueued="0" />
<timesms mark="408.282" sweep="5.061" compact="0.000" total="415.341" />
<tenured freebytes="209018360" totalbytes="402653184" percent="51" >
<soa freebytes="209018360" totalbytes="402653184" percent="51" />
<loa freebytes="0" totalbytes="0" percent="0" />
</tenured>
</gc>
<tenured freebytes="209013328" totalbytes="402653184" percent="51" >
<soa freebytes="209013328" totalbytes="402653184" percent="51" />
<loa freebytes="0" totalbytes="0" percent="0" />
</tenured>
<time totalms="417.431" />
</af>
Vu l’allure du log, on a pas l’impression d’être sur un GC de type generationnel, mais je ne suis pas encore sûr, c’est une JVM IBM. Bon revenons à nos moutons:
- il y a eu 230 ms d’écoulées avant le dernier GC.
- la tenured indique directement qu’il n’y a plus de place dans la mémoire,
- on voit que le GC est de type global, ce qui veut dire que c’est toute la zone mémoire qui est affectée par le GC, c’est long
- la tenured libère environ 200 MB, soit 51%!
- le temps total mis par ce GC est de 420 ms, c’est long.
Et il y a plein d’entrées comme ça, ça fait beaucoup de GC globaux de 1 demi-secondes, tous les 5ème de secondes. Le GC prends du temps CPU pour nettoyer la mémoire un peu trop souvent. Et ce ci pourrait bien être la cause des ralentissements observés. En gros soit il n’y a simplement pas assez de mémoire, soit il y a une fuite mémoire.
Avec : IBM Support Assistant et Garbage Collection and Memory Visualizer
En me renseignant, je voulais jeter un œil aux outils IBM plus récents, tel que celui mentionné par http://www-01.ibm.com/software/support/isa/.
Après une fois qu’on a l’outil, il faut à nouveau télécharger des plugins (nommé additif sur l’interface en français). Bon en fait le Health Center en me sert à rien puisqu’il il faut se connecter à une JVM IBM, ayant une JVM Sun sur mon poste je ne vais quand même pas aller taper sur la prod si tenté que ce soit possible. Finalement j’opte pour le plugin : Garbage Collection and Memory Visualizer.
Donc finalement j’essaye cet outils d’analyse, et j’ai un rapport bien plus sympa et complet avec plein de graphiques qui m’intéressent.
Déjà le rapport débute par :
Your application appears to be leaking memory. This is indicated by the used heap increasing at a greater rate than the application workload (measured by the amount of data freed). To investigate further see Guided debugging for Java
Ok, je m’en doutais déjà mais c’est quand même mieux que de dire que la mémoire est quasiment entièrement utilisée. Et on retrouve les alertes suivantes dans le rapport :
The application seems to be using some quite large objects. The largest request which triggered an allocation failure (and was recorded in the verbose gc log) was for 5242904 bytes.
5MB quand même! Cela dit ça n’arrive pas souvent, c’est peut-être un cache qui charge des données depuis le disque. Le graphe suivant (choisir Object Size dans les templates de graphique sur la droite) montre la taille des allocations demandées.
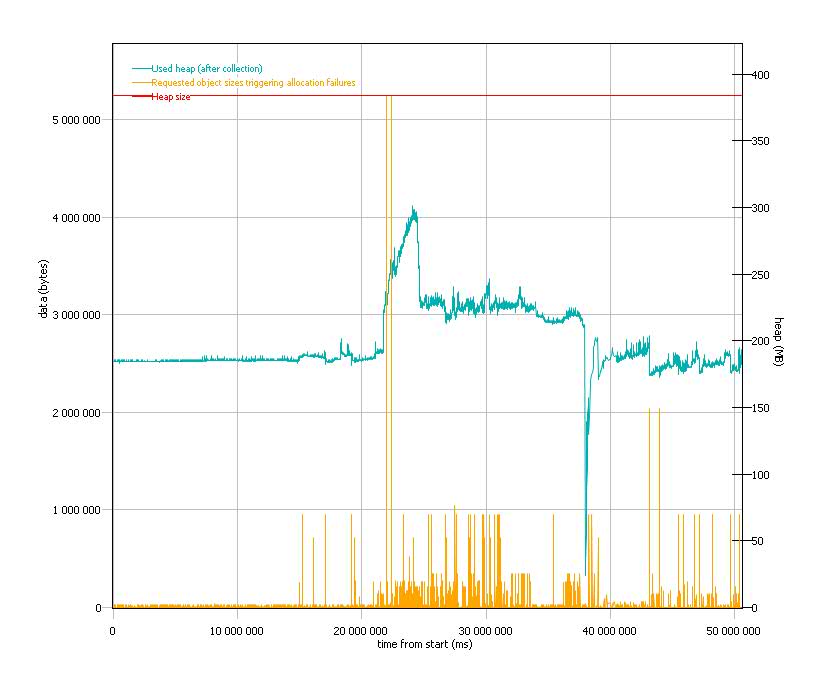
Mais la concomitance de ses demandes d’allocation avec l’utilisation de la heap fait sourciller.
On continue
Garbage collection is causing some large pauses. The largest pause was 7362 ms. This may affect application responsiveness. If responsiveness is a concern then a switch of policy or reduction in heap size may be helpful.
Effectivement le temps passé dans l’application et le temps passé dans le GC indique manifestement qu’il y a une suractivité anormale du GC.
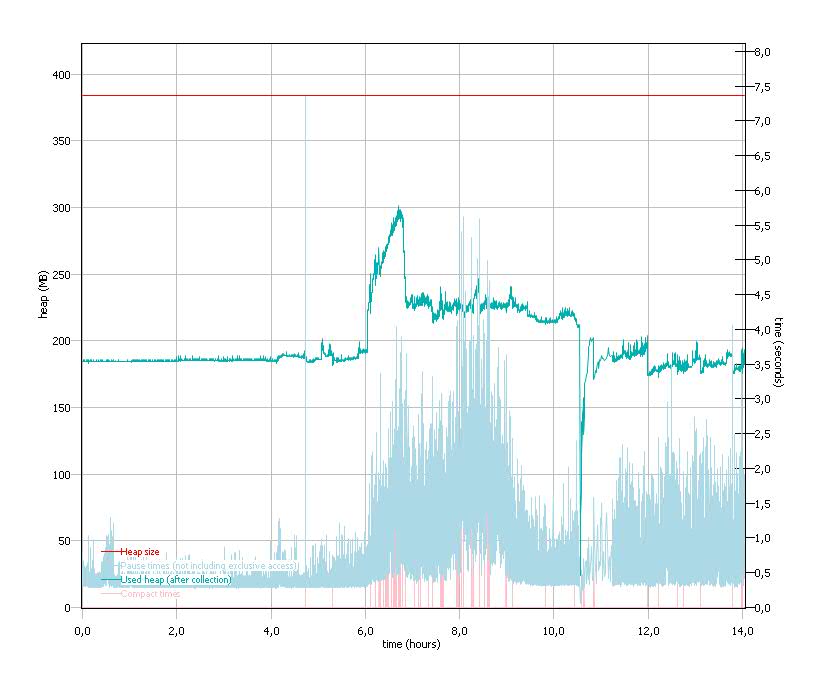
En fait on voit même que le GC est en train de compacter la mémoire au moment de l’incident, c’est la courbe rouge clair (entre ~0.5s et 1s), ajouté à cela le temps de marquage des objets à virer (bon en fait dans le graphique que j’ai fait, le temps de pause est principalement du au temps de marquage), l’ensemble donnant un temps de pause pour laisser le GC travailler allant de 1 à 7s (par GC bien évidement).
Et là effectivement expliquer les ralentissements de l’application devient plus facile, merci à ces beaux graphiques explicites.
On peut regarder vraiment beaucoup de chose avec cet outils, même s’il y a des défauts manifestes dans l’interface utilisateur. C’est quand même plutôt pas mal.
Je termine sur un petit résumé des valeurs intéressantes que nous donne cet outils.
| Allocation failure count | 59971 |
|---|---|
| Forced collection count | 3 |
| GC Mode | optthruput |
| Largest memory request (bytes) | 5242904 |
| Mean garbage collection pause (ms) | 491 |
| Mean heap unusable due to fragmentation (MB) | 0.2 |
| Mean interval between collections (minutes) | 0.01 |
| Number of collections | 59974 |
| Proportion of time spent in garbage collection pauses (%) | 58.24 |
| Proportion of time spent unpaused (%) | 41.76 |
| Rate of garbage collection (MB/minutes) | 13250 |
Tiens le mode GC est optthruput, en fait c’est une des polices du comportement du GC, et probablement de la manière de segmenter la mémoire (Nursery (Young), Old (Tenured)).
En effet dans les logs GC, je n’ai pratiquement vu que des GC globaux et uniquement sur la section de la tenured, à priori pas de zone nursery, c’est probablement du à ce comportement du GC.
En me renseignant donc, il y a 4 polices de GC dans la JVM J9 de IBM :
optthruput: Optimisé pour throughput (le débit), flat heap <= Bingooptavgpause: Optimisé pour les temps de pause (Stop-The-World), le CMS est configuré pour prendre le moins de temps, flat heapsubpool: Un police optimisé pour les machine multi-processeur, flat heapgencon: C’est le GC générationnel, qui est divisé en zonenursery: qui permet la collection rapide et efficace des objets de vie courte, pas de pausetenured: zone des vieux objets, mais un GC dans cette zone est global et demande à pauser l’application
A la poursuite du vrai problème (partie 2)
La pèche aux informations
Après avoir passé le GC au mode générationnel, il y a toujours ces problèmes de lenteurs mais ce n’est plus généralisé à toute l’appli, pas de log GC pour vérifier mais Introscope indique une utilisation relativement correcte de la mémoire, bizarre. Back to basics!
Le thread dump de la JVM IBM me dit toujours que la Heap est utilisée à 100%, mais je vois quand même
Free Java heap size: 72 041 864 bytes
Allocated Java heap size: 402 653 184 bytes
Et plus loin :
Last Garbage Collection Detail
Nursery Area Free : 59 307 392 bytes Total : 60 397 568 bytes 98% free
Tenured Area Free : 17 058 368 bytes Total : 335 544 320 bytes 5% free
Global Garbage Collector Counter : 148
La tenured est bien remplie et utilise un très grosse partie de la heap ; memory leak ou beaucoup d’objet à mettre en cache. Ou encore autre chose, sans mesures claires pour écarter les hypothèses ces dur.
Pour quoi ne pas activer dans tous les cas le log GC, la JVM IBM offre des option pour gérer la rotation des logs GC, comme ça l’argument de saturation du disque tombe à l’eau. Mais bon il faut lire la documentation; donc petit passage chez IBM grâce à Google, et hop :
-Xverbosegclog[:<file>[,<x>,<y>]]
Et voilà : file étant le couple chemin + fichier, X le nombre de fichier maximum (ça tourne et écrase les fichiers), Y le nombre de cycle GC. Ce que ne dis pas par contre la doc IBM c’est la taille approximative d’un GC, donc 700 cycles de GC ≃ 1 MB. Il est même possible d’utiliser des tokens utilisés pour les dumps dans WAS 7 (voir ici).
Recoupement des informations
Le log du Garbage Collector ne venant pas, il faut chercher autrement. Je demande au moment ou le problème se reproduit , de faire plusieurs thread dump d’affilé séparé de quelques secondes (~20s) et de faire également un listing des sous-processus java.
En effet le thread dump est bien sympa, mais il ne donne pas la consommation CPU des threads.
Dans un environnement il faut entre dans le terminal (Dans Linux l’identifiant des thread est dans la colonne LWD.) :
ps -fLp <processid> -L
Evidement il s’agit d’un AIX et les commendes sont différents, pas de soucis un petit tour dans la doc IBM et il faut entrer la commande suivante, et là l’identifiant de la thread est dans la colonne TID :
ps -mp -o THREAD
On a alors un listing énorme, que j’ai tronqué ici.
USER PID PPID TID S CP PRI SC WCHAN F TT BND COMMAND
wasadmin 393262 401580 - A 188 60 203 * 202001 - - /opt/was61/java/bin/java ...
- - - 700535 S 0 82 1 f100070f1000ab40 8410400 - - -
- - - 741581 S 0 82 1 f100070f1000b540 8410400 - - -
- - - 802997 S 0 82 1 f100070f1000c440 8410400 - - -
- - - 884895 S 0 82 1 f100070f1000d840 8410400 - - -
- - - 1183791 Z 0 82 1 - c00001 - - -
- - - 1667157 R 60 122 0 - 400000 - - -
- - - 1708269 S 0 82 1 f100070f1001a140 8410400 - - -
- - - 1736831 S 0 82 1 f100070f1001a840 8410400 - - -
La colonne CP me dit que manifestement la thread 1667157 utilise plutôt pas mal le CPU, qu’est-ce que donne cette thread du coté du thread dump ?! Au fait on repère 3 threads dans le même cas.
Il faut savoir que dans le thread dump il y a l’identifiant de la thread en Java, mais qu’il y a aussi et surtout de mentionné l’identifiant natif de la thread, par exemple NID.
Je google “1667157 in hex” ce qui me renvoie 0x197055. En utilisant l’outils IBM mentionné plus haut, on voit clairement que la thread en cause correspond à du code métier, développé ici.
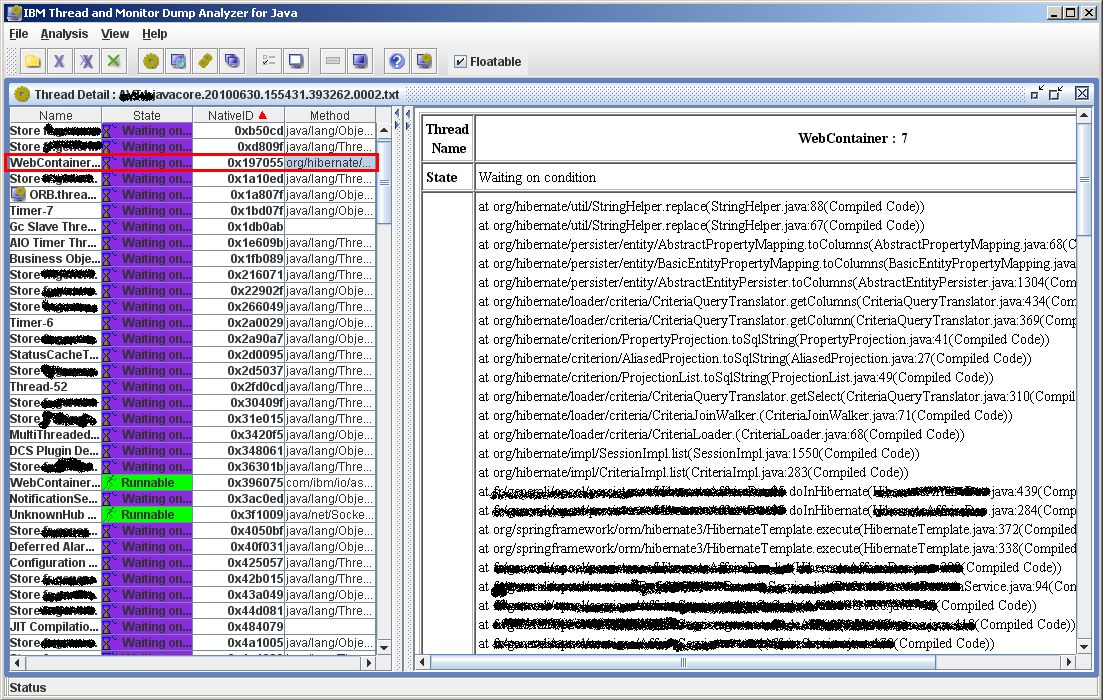
Chacune des 3 threads passent dans le même bout de code. Autant au début j’ai des doutes, après toute la présomption d’innocence compte aussi pour le code, d’autant plus qu’il s’agit d’un code lent qui utilise beaucoup de reflection. Mais faut prendre en compte aussi le fait que la pile descend à chaque fois dans la couche Hibernate, ça vaut le coup d’aller voir. Les développeurs qui connaissent un peu mieux le code poussent dans cette direction.
Entre temps les DBA confirme que la base de données réponds très bien, mais qu’elle enregistre un très fort nombre d’un certain type de requête SQL.
Bingo, il y a une race condition dans une des boucles, et celle-ci part en boucle infinie. Ceci explique la très forte utilisation de la mémoire et les lenteurs remarquées.
Bilan
Un problème peut en cacher un autre, ou plus exactement un problème peut en provoquer d’autres. Il faut juste avoir des moyens de mesurer les changements qu’on apporte si on veut isoler / écarter des catégorie de problèmes.
L’outillage on l’a vu est essentiel, Introscope apporte des choses, mais il ne permet pas tout. Qui plus est, on ne sait pas précisément ce qu’il mesure et ou! Les temps de réponses SQL, n’étaient par exemple pas crédible, car Introscope mesurait également les GC.
Dans notre cas ici, j’aurais aussi bien aimé avoir une JVM IBM sur mon poste histoire de jouer plus facilement avec. C’est dommage que IBM ne fournisse pas gratuitement sa JVM au moins pour le développement.
Accessoirement ce serait bien un jour d’avoir des format de log normalisé entre les JVM, ainsi que certaines des options afférentes.
Finalement ce qui a pris le plus de temps était d’obtenir les bonnes données, pour prendre les meilleurs choix. L’impression de travailler les mains dans le noir n’était pas l’idéal pour résoudre le problème, mais c’est au moins formateur. Je peux dire que j’ai bien apprécié certains retours et recommandations des développeurs. L’équipe système étant surchargée n’a pas pu nous donné un support optimal, et cette carence s’est ressentie notamment pour avoir les données à temps. Mais leur vu du problème a permis d’orienter la recherche sur les parties qui pouvait poser problème.
Références & Documentation
- http://websphere.sys-con.com/node/921279?page=0,1
- http://sites.google.com/site/threaddumps/java-thread-dumps
- http://java.sun.com/developer/technicalArticles/Programming/Stacktrace/
- http://geekexplains.blogspot.com/2008/07/threadstate-in-java-blocked-vs-waiting.html
- http://www.ibm.com/developerworks/java/library/j-nativememory-aix/
- http://www.ibm.com/developerworks/ibm/library/i-garbage1/
- http://www-01.ibm.com/support/docview.wss?rs=180&context=SSEQTP&dc=DB560&dc=DB520&uid=swg21384096&loc=en_US&cs=UTF-8&lang=en&rss=ct180websphere
- http://publib.boulder.ibm.com/infocenter/javasdk/v6r0/index.jsp?topic=/com.ibm.java.doc.diagnostics.60/diag/appendixes/cmdline/cmdline_gc.htm