
Kafka, a walking skeleton
Ce blog post est une republication de mon article sur Kafka parut dans le magazine Programmez numéro 196 en mai 2016 (pages 70-73). Il se base sur la version 0.9 de Kafka.
Vous avez entendu parlé de Kafka et vous voulez en savoir plus. En ingénierie logicielle un walking skeleton est un système minimal qui fonctionne de bout en bout. J’espère que cette introduction vous sera utile pour démarrer cette première implémentation.
Kafka encore un autre broker de message ?
Ce projet vient tout droit de LinkedIn, lorsque des ingénieurs ont identifié des problèmes de performance globaux dans leur traitement de données. Fin des années 2000, BigTable, Hadoop et MapReduce sont des buzzwords de l’IT. Cependant, les approches proposées reposent sur des traitements de type batch et ne permettent donc pas de traiter de gros volumes de données en temps réel.
Afin de correspondre aux besoins de l’environnement de production de LinkedIn les ingénieurs avait besoin d’une solution technique répondant aux critères suivants :
- Haute Performance
- Durabilité des messages
- Scalabilité
- Résilience aux pannes
- Simplicité
Cette solution s’appelle Kafka, LinkedIn en a fait un projet Open Source.
En terme de performance, Kafka devance de très loin tous les autres acteurs avec une charge encaissée de plus de 100k messages/secondes (certaines configurations de LinkedIn montent jusqu’à 2 Millions/secondes). Kafka “stocke” durablement les messages, c’est-à-dire qu’ils ne sont pas effacés à la consommation ; la rétention est réglable. Un critère important pour un site comme LinkedIn est de pouvoir monter en charge en fonction du besoin. Pour cette raison, la topologie d’un cluster Kafka peut être modifiée au besoin : ceci permet de scaler horizontalement. Pour anticiper les pannes ou les interventions sur les machines, Kafka réplique ses données sur plusieurs serveurs ce qui le rend relativement résilient aux pannes. Enfin Kafka est simple car sa conception se veut basée sur une primitive simple – le log ; également son utilisation reste simple car il ne propose que du queuing et du publish/subscribe.
Comment ça marche
Dans les faits le log est utilisé par de nombreux systèmes, par exemple dans les bases de données, cependant ils n’exposent pas ce log à l’utilisateur, tout au plus à l’administrateur système. En revanche avec Kafka, le log est exposé à l’utilisateur et il est au cœur de sa conception.
Une des primitives de base est le topic. Les messages sont publiés dans un topic par des producers (producteurs) et les consumers (consommateurs) souscrivent à ce même topic pour traiter ces messages. Schématiquement une infrastructure utilisant Kafka peut être représenté de cette façon :
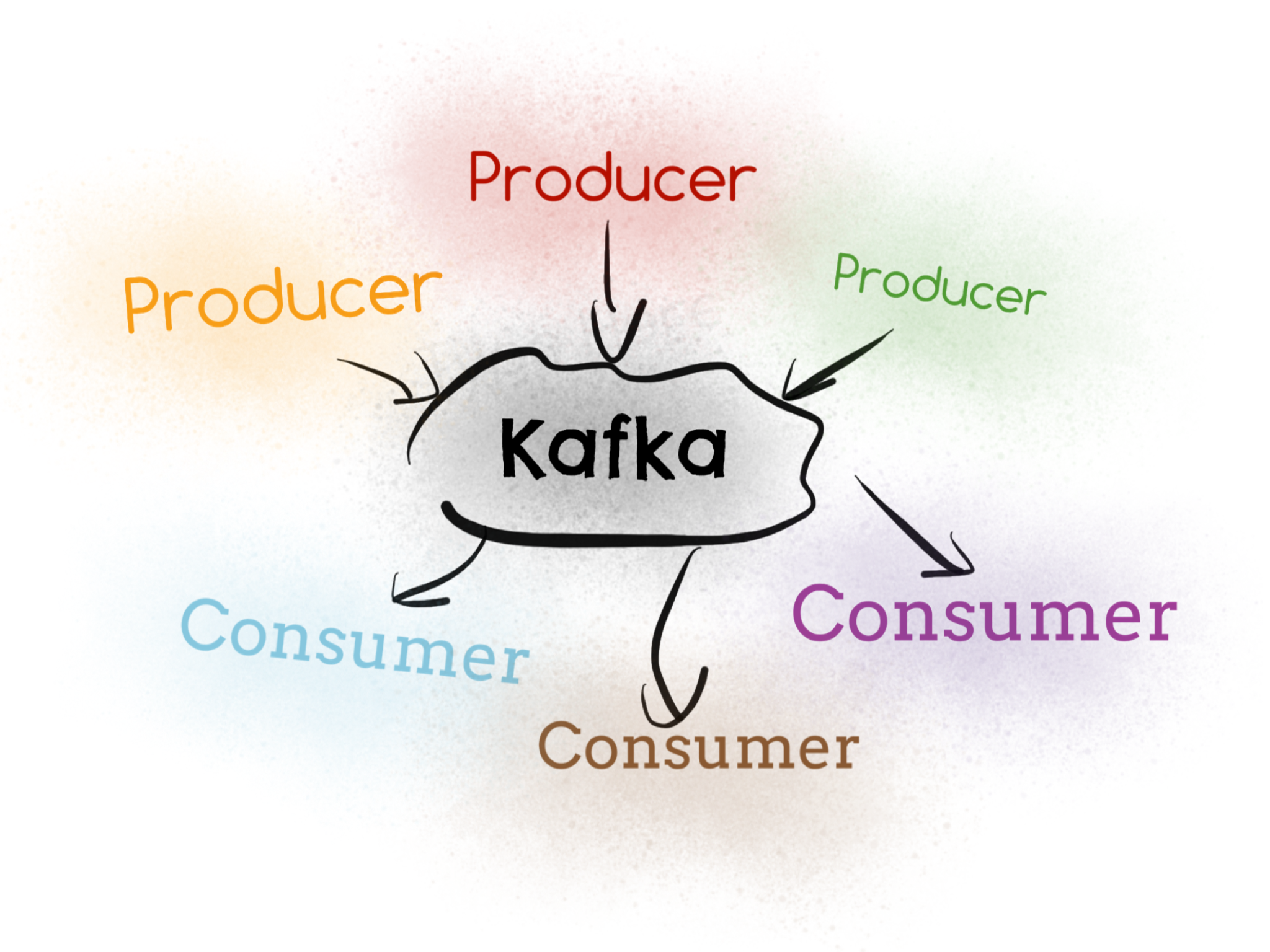
Techniquement un topic est un log partitionné auquel les messages sont ajoutés continuellement et ceci de manière ordonnée (dans une même partition). Pourquoi est-ce partitionné ? Avec Kafka il y a une relation forte entre le nombre de partitions et le nombre de consommateurs ; augmenter le nombre de partition revient à augmenter le parallélisme des consommateurs.
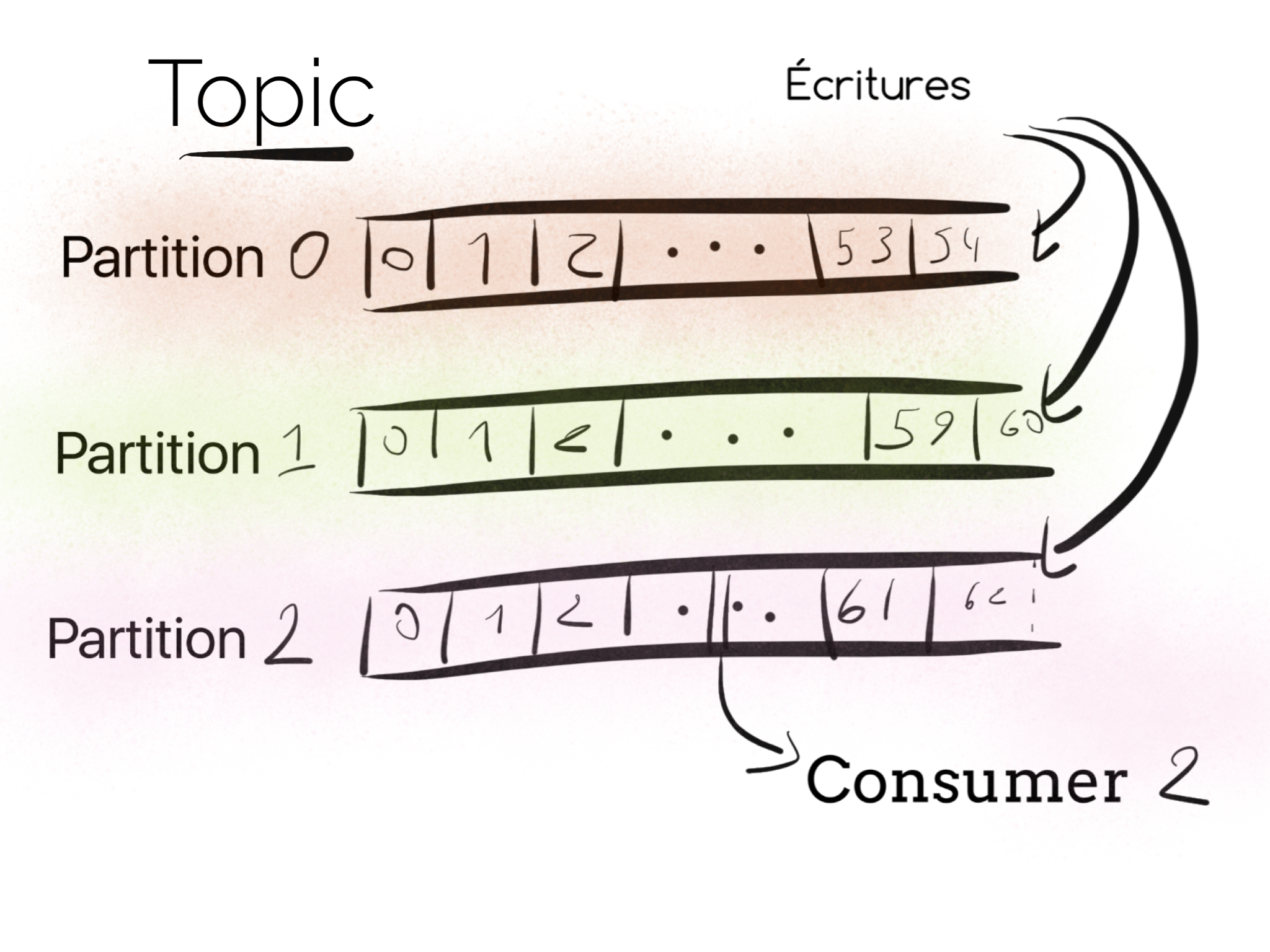
Les producers et les consumers
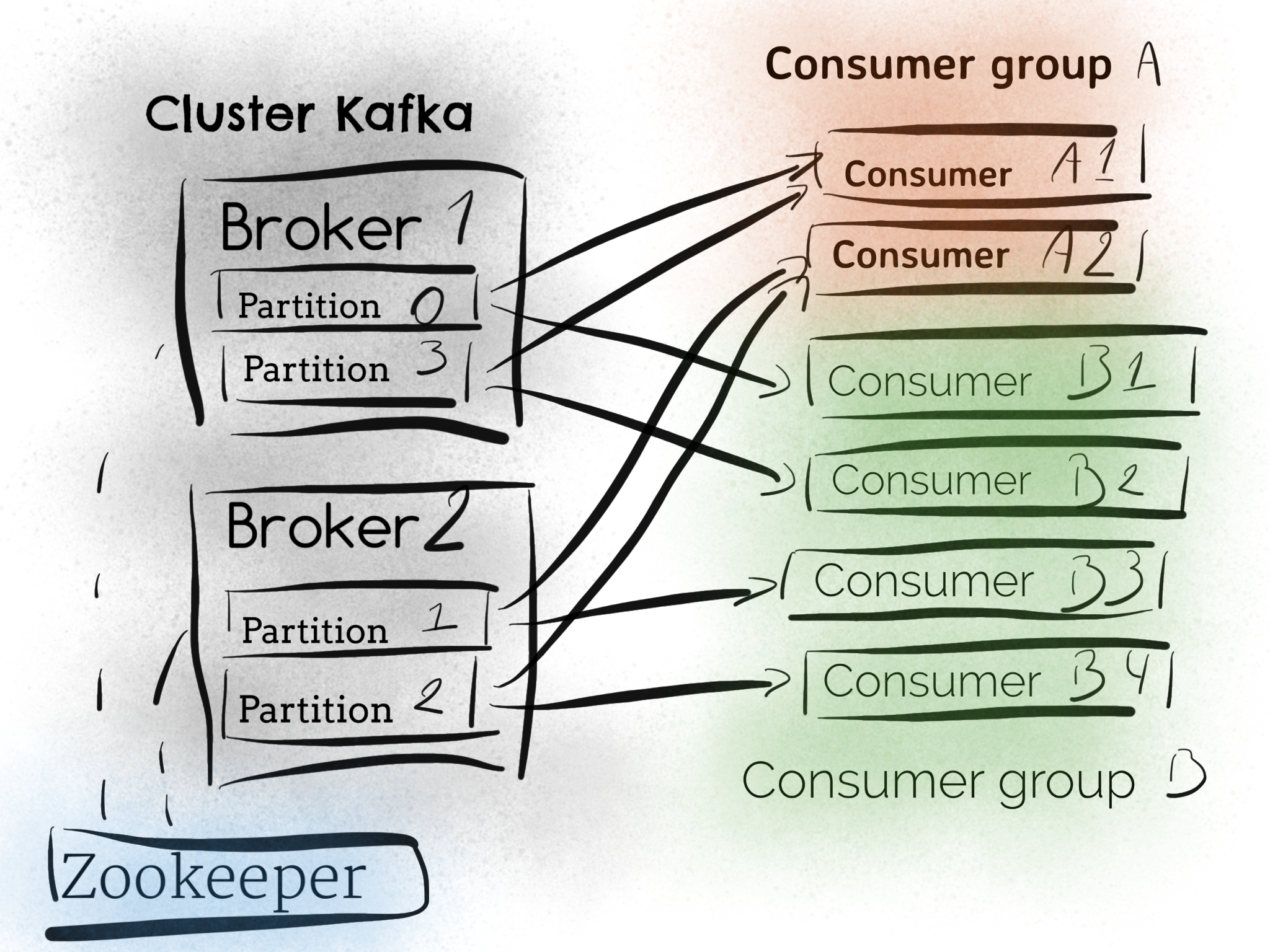
Kafka fournit une abstraction appelé consumer group (groupe de consommateurs) qui généralise à la fois les deux patterns queuing et publish/subscribe. Chaque consommateur s’attribue un groupe, et, pour chaque message sera délivré à une seule instance dans le groupe.
- Tous les consumers ont le même groupe, c’est du queuing, ou la charge est répartie sur chaque consommateur.
- Les consumers ont un groupe différent, dans ce cas c’est du publish/subscribe.
À noter sur le parallélisme, au sein d’un même consumer group, pour N partitions il ne peut y avoir que N consumers actifs. Il peut y avoir plusieurs consumer groups abonnés à un même topic (et donc sur les même partitions).
À propos de la réplication
Chaque partition d’un topic est répliquée suivant la configuration donnée. Parmi tous les réplicas (les serveurs qui ont une copie des partitions d’un topic) :
- L’un sera le leader, c’est celui-ci qui va traiter les demandes de lectures / écritures
- Les autres sont des followers (suiveurs), leur but est de répliquer passivement les partitions.
Si le leader s’arrête, un des suiveurs prend le relais et devient le nouveau leader pour les partitions affectées.
À noter que chaque serveur agit en tant que leader pour certaines partitions et en tant que follower pour d’autres partitions, ce qui permet de garder un cluster équilibré.
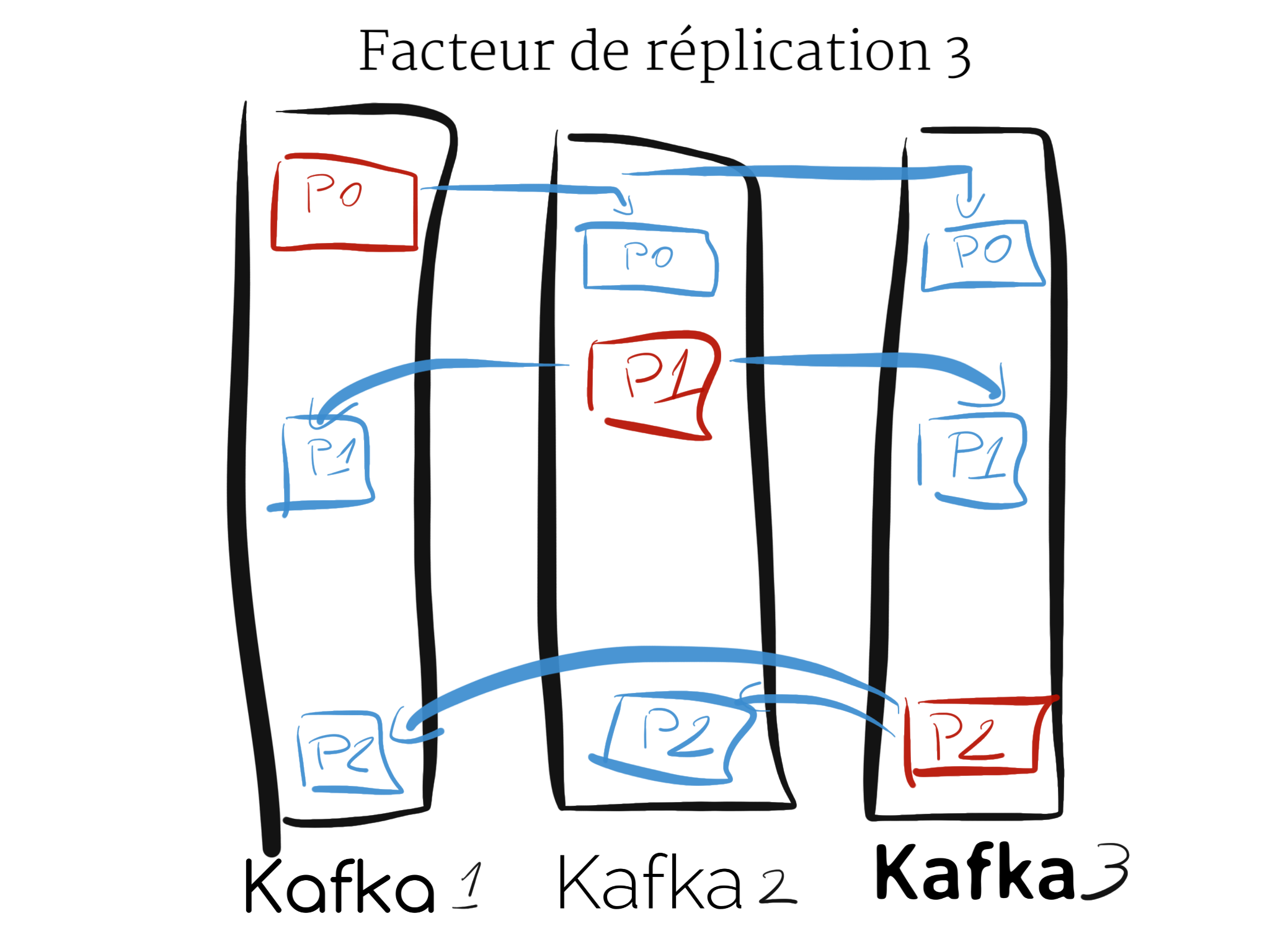
En rouge sont ce sont les partitions dont un des serveur Kafka est le leader, c’est donc la partition en rouge qui recevra les écritures des producers. En bleu sont dessinées les partitions répliquées.
Pour cette introduction, ces quelques explications devraient suffire. Il y a bien sûr davantage de ressources à la fois sur le site officiel de Kafka (kafka.apache.org) et sur le site de la société commerciale de Kafka (http://confluent.io).
Mettre en place Kafka
Cet article se base sur la version 0.9.0.x. La sous version Scala n’a pas vraiment d’importance si vous ne faites pas de Scala. La version utilisant Scala 2.11 est d’ailleurs recommandée.
Démarrer avec 1 seule instance
Kafka utilise Zookeeper pour stocker ses métadonnées. Il faut donc le lancer en premier. Dans un terminal à part, lancez la commande :
$ cd kafka_2.11-0.9.0.1
$ ./bin/zookeeper-server-start.sh ./config/zookeeper.properties
Pour vérifier son état de marche, on peut envoyer le mot de 4 lettres stat sur le port 2181, le port de communication client.
$ { echo stat; sleep 0.1 } | telnet 127.0.0.1 2181
Trying 127.0.0.1...
Connected to localhost.
Escape character is '^]'.
Zookeeper version: 3.4.6-1569965, built on 02/20/2014 09:09 GMT
Clients:
/127.0.0.1:52946[0](queued=0,recved=1,sent=0)
Latency min/avg/max: 0/0/0
Received: 1
Sent: 0
Connections: 1
Outstanding: 0
Zxid: 0x0
Mode: standalone
Node count: 4
Connection closed by foreign host.
Si vous avez ces statistiques alors le serveur Zookeeper tourne correctement. S’il y a un autre message alors le cluster Zookeeper n’est pas dans la bonne configuration et n’est donc pas opérationnel.
Ensuite démarrons une instance Kafka. Il faut donner les valeurs aux propriétés suivante dans le fichier
config/server.properties :
broker.id=1
port=9092
logs.dirs=/tmp/kafka-logs-1
zookeeper.connect=localhost:2181
Enfin lancer la première instance.
$ ./bin/kafka-server-start.sh ./config/server.properties
Ensuite nous pouvons créer le premier topic, c’est en ligne de commande que ça se passe :
$ ./bin/kafka-topics.sh --create \
--topic bier-bar \
--partition 3 \
--replication-factor 1 \
--zookeeper localhost:2181
Les métadonnées du topic sont donc créées sur le cluster Zookeeper. Notez les paramètres obligatoires que sont le nombre de partitions et le facteur de réplication.
Il est possible de produire et de consommer des messages avec les outils en ligne de commande inclus dans la
distribution (kafka-console-producer.sh et kafka-console-consumer.sh). Ceci dit cet article se concentre plutôt sur
le code Java.
Au niveau code
Avec la version 0.9, il faut importer la dépendance org.apache.kafka:kafka-clients:0.9.0.1, elle est nécessaire pour
utiliser l’API java de Kafka à la fois pour produire et consommer des messages.
Le code minimal pour créer un producteur de données, en premier lieu il faut trois propriétés :
- La liste des serveurs kafka Les classes de sérialisation pour la clé et la valeur
Ensuite il suffit de produire des messages sur le topic créé.
public static void main(String[] args) throws InterruptedException {
Properties props = new Properties();
props.put(BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
props.put(VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
Runtime.getRuntime().addShutdownHook(new Thread() {
public void run() {
System.out.println("Barman shutting down ...");
// always close the producer
// timeout to allow the producer to send the data to the broker
producer.close(1000, MILLISECONDS);
}
});
while (true) {
producer.send(new ProducerRecord<>("bier-bar",
String.format("Bier bought at '%s'",
LocalTime.now())));
SECONDS.sleep(1);
}
}
Cette classe enverra des messages simples, qu’un consommateur traitera dans un autre process de l’infrastructure.
Le code minimal du consommateur est le suivant, également la configuration minimale est la même aussi les adresses des broker Kafka, les classes désérialisation, et enfin l’identifiant de groupe. À noter, étant donné que ce code utilise la nouvelle API Java apparue en version 0.9, il n’y a pas besoin de gérer la connexion à Zookeeper.
public static void main(String[] args) {
Properties props = new Properties();
props.put(BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(GROUP_ID_CONFIG, "barfly-group");
props.put(KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.put(VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Collections.singletonList("bier-bar"));
try {
for(int i = 0; i < 10; i++) {
ConsumerRecords<String, String> records = consumer.poll(1000);
for (ConsumerRecord<String, String> record : records)
System.out.println(record.offset() + ": " + record.value());
}
} finally {
System.out.println("Barfly shutting down ...");
consumer.close(); // always close the consumer
}
}
Dans cette configuration le consommateur ne fera que 10 opération de polling, après quoi il s’arrêtera. En le lançant une seconde fois, seul les nouveaux messages seront dépilés. Ce comportement est modifiable, ainsi plutôt que de reprendre à la position du dernier message consommé, il est possible de choisir la position et donc, par exemple, de reprendre un topic depuis le début.
Le code présenté ici est simple, il est facile de le réutiliser pour jouer sur le parallélisme ou les topologies de consommateurs avec les groupes de consommateurs. Typiquement au sein d’un consumer group, une partition ne sera assignée qu’à un seul consumer. Pour un besoin métier différent il faudra qu’un consommateur ait un autre group.id.
À noter qu’un consommateur n’est pas thread-safe, il prévu pour tourner dans un thread qui lui est dédié. Ainsi on peut
imaginer soumettre des taches de consommation de message sur un ExecutorService :
executorService.submit(new Barfly());
Cette tâche n’aurait qu’à étendre la classe Runnable :
public class Barfly implements Runnable {
// ...
@Override
public void run() {
System.out.printf("Starts consumer %s%n", uuid);
consumer.subscribe(Collections.singletonList("bier-bar"));
try {
while (true) {
ConsumerRecords<String, String> records = consumer.poll(1000);
for (ConsumerRecord<String, String> record : records) {
System.out.printf("%d:%s:%s -> %s%n",
record.partition(),
record.offset(),
uuid,
record.value());
}
}
} catch(WakeupException ignored) {
} finally {
System.out.println(String.format("Barfly '%s' shutting down ...", uuid));
consumer.close(); // always close the consumer
}
}
public void shutdown() {
consumer.wakeup();
}
}
À noter que pour stopper proprement le thread du consumer, il est possible d’invoquer consumer.wakeup(). Dans cet
exemple une WakeupException sera levée afin d’interrompre la boucle infinie, ce qui permet d’atteindre le bloc finally
pour clore le consumer.
La sérialisation / désérialisation
Kafka ne gère que des octets, il n’a pas connaissance du contenu réel d’un message. C’est pour cette raison que les producteurs et les consommateurs ont besoin d’avoir des classes qui font la traduction entre la représentation Java et un tableau d’octets.
Par exemple StringSerializer doit juste transformer un String en tableau d’octets. Coté désérialisation, c’est le
travail inverse qui est fait. Sur des messages simples, une chaîne de caractères, utiliser le StringSerializer peut
suffire, en revanche, s’il s’agit de faire passer des grappes d’objets plus complexes, alors il faut passer à autre
chose.
Pour cette article imaginons que les messages doivent être sérialisé en JSON, il est possible d’écrire ce sérializeur JSON, de la façon suivante avec les librairies du projet Jackson.
public class JsonSerializer<T> implements Serializer<T> {
private ObjectMapper objectMapper = new ObjectMapper().setVisibility(PropertyAccessor.FIELD,
Visibility.NON_PRIVATE)
.registerModules(new Jdk8Module(),
new JavaTimeModule());
// ...
@Override
public byte[] serialize(String topic, T data) {
try {
return objectMapper.writeValueAsBytes(data);
} catch (JsonProcessingException e) {
e.printStackTrace();
throw new UncheckedIOException(e);
}
}
// ...
}
Ce qui donnerait le message suivant, :
0:1400 -> {"message":"Bier served","bierName":"Gallia","timestamp":\[16,0,6,509000000\]}
Notez que le message est bien sous forme de string. Le premier Barfly consommateur pourra lire ce message comme une
String. En revanche pour transformer ce message dans un objet Java, il faut faire la même chose avec un désérialiseur,
le code de ce désérialiseur n’en sera pas plus complexe.
Attention ceci dit JSON ou autre représentation non binaire n’est pas optimale. Si votre format de message doit être amener à évoluer, il sera plus judicieux d’utiliser Avro ou un équivalent. Avro ou d’autres solutions peuvent également avoir de l’attrait en terme d’empreinte mémoire et de performance.
Dans une infrastructure qui fait communiquer des applications entre elles, que ce soit par HTTP, avec Kafka ou une autre technologie, il faut tester fortement les outillages de sérialisation, penser aux montées de version des messages, ainsi qu’au coût que la sérialisation peut engendrer en terme de performance.
Focus sur Zookeeper
Jusqu’ici Zookeeper est assez peu évoqué. C’est un composant nécessaire de Kafka. En version 0.9 de Kafka il a deux rôles très important :
- Service Discovery des instances Kafka Stockage des métadonnées des topics
Afin de permettre un rééquilibrage de la charge des brokers, ceux-ci doivent se connaître, ils utilisent pour cela Zookeeper en tant que registre.
Comme on l’a vu plus haut, l’outillage d’administration créer un topic sur Zookeeper, car il agit là aussi comme registre de métadonnées.
Il est nécessaire qu’il soit démarré en premier et qu’il soit arrêté après Kafka. Pour ces raisons Zookeeper représente un élément sensible de l’infrastructure. Il faut donc lui accorder le plus grand soin. Connaître ce produit est plus qu’un simple bonus.
Mon avis personnel est de prendre la distribution officielle de Zookeeper plutôt que de prendre le Zookeeper livré dans la distribution Kafka, la distribution Zookeeper contient des outils additionnels intéressants pour les opérations pour gérer le cluster Zookeeper.
En production, où la haute disponibilité est un prérequis, on pensera à affecter au minimum trois machines dédiés pour chacune des instances du cluster Zookeeper. L’emplacement de ces machines sera de préférence dans des armoires différentes. Cette utilisation des ressources matérielles autorisera des interventions, par exemple sur les alimentations électriques.
Sur un petit SI, ou une durée d’indisponibilité est autorisée, une seule instance Zookeeper sur une machine dédiée suffira.
Dans tous les cas il faut éviter de faire tourner les brokers Kafka sur les mêmes machines que Zookeeper. Si une machine hébergeant à la fois Zookeeper et Kafka tombe alors cela peut mener à la corruption de données de topologie du cluster Kafka et donc d’interrompre le service.
À noter que Zookeeper n’est pas encore équipé d’auto-discovery ni d’ajout d’instance à la volée. Le travail est en cours sur la version 3.5, il faudra donc bien dimensionner son cluster Zookeeper. Aujourd’hui en version 3.4.x il faut lancer une procédure de rolling restart, en ajoutant dans la configuration une nouvelle instance à la fois.
En production
Kafka peut manquer de maturité, mais l’outil est considéré production-ready. Il fonctionne très bien en environnement de production, des noms comme Linkedin, Twitter, Uber, Netflix, Spotify le prouvent chaque jour.
La société Confluent vend du support technique, et finance le développement de Kafka ; la société a été fondé par les ingénieurs de LinkedIn à l’origine du projet.
Pour amener Kafka en production l’idéal est de travailler sur une fonctionnalité simple. Ainsi il est possible d’avoir des retours techniques grâce au trafic réel de production, et des retours humains par l’exploitant. Ce code devra bien sûr être activable à la demande (feature toggle) afin de ne pas compromettre la production.
Les points d’attention
Comme tous les produits il y a des points forts et des éléments à améliorer, même si Kafka tourne sur certaines des plus grosses productions du monde il n’en reste pas moins jeune sur certains aspects :
- En phase de développement, l’outillage de test est assez maigre.
- Comme tous les brokers il faut que l’équipe comprenne les contraintes et la sémantique qui entourent le messaging, en particulier at-least-once et l’ordre des messages.
- La configuration de Kafka est simple, mais si la configuration des machines est plus avancée (plusieurs interfaces réseau, noms de domaine interne, etc.) alors la documentation commence à montrer ses lacunes.
- En environnement d’exploitation, l’expérience pourrait être améliorée. Typiquement le rééquilibrage d’un cluster est une opération qui pourrait être simplifiée.
- Kafka ne vient pas avec une interface graphique d’administration, il existe le projet KafkaManager maintenu par des gens de Yahoo, mais celui-ci n’a pas exactement le même cycle de vie que Kafka.
Pour finir
Kafka est encore jeune, mais offre une alternative intéressante et performante aux systèmes actuels. Réaliser un comparatif avec d’autres acteurs du marché n’est pas forcément pertinent, il faut avant tout identifier ses besoins.
Si le besoin d’un broker avec des fonctionnalités plus avancées comme le support des transactions, les garanties de d’ordre alors Kafka n’est peut-être pas le bon outil.
Par contre si les critères primordiaux sont de pouvoir encaisser une forte charge, de pouvoir ajouter des instances suivant le besoin, ou de persister durablement les messages, alors Kafka est une option sérieuse à envisager.
Sources
- Walking skeleton
- kafka
- 2 million writes second three at LinkedIn on cheap hardware
- Differences between Apache Kafka and RabbitMQ (question on Quora)
- Confluent
- Using logs to build a solid data infrastructure (or: why dual writes are a bad idea)
- How to choose the number of topics/partitions in a Kafka cluster?
- The Four Letter Words
- Post-deployment doc
Code