
Anonymous CompletableFuture threads with burstable pods
Short-lived anonymous Threads
It all started when opening a JFR recording, I noticed a very large and growing number of very short-lived anonymous threads. Was it bad coding, or something else?
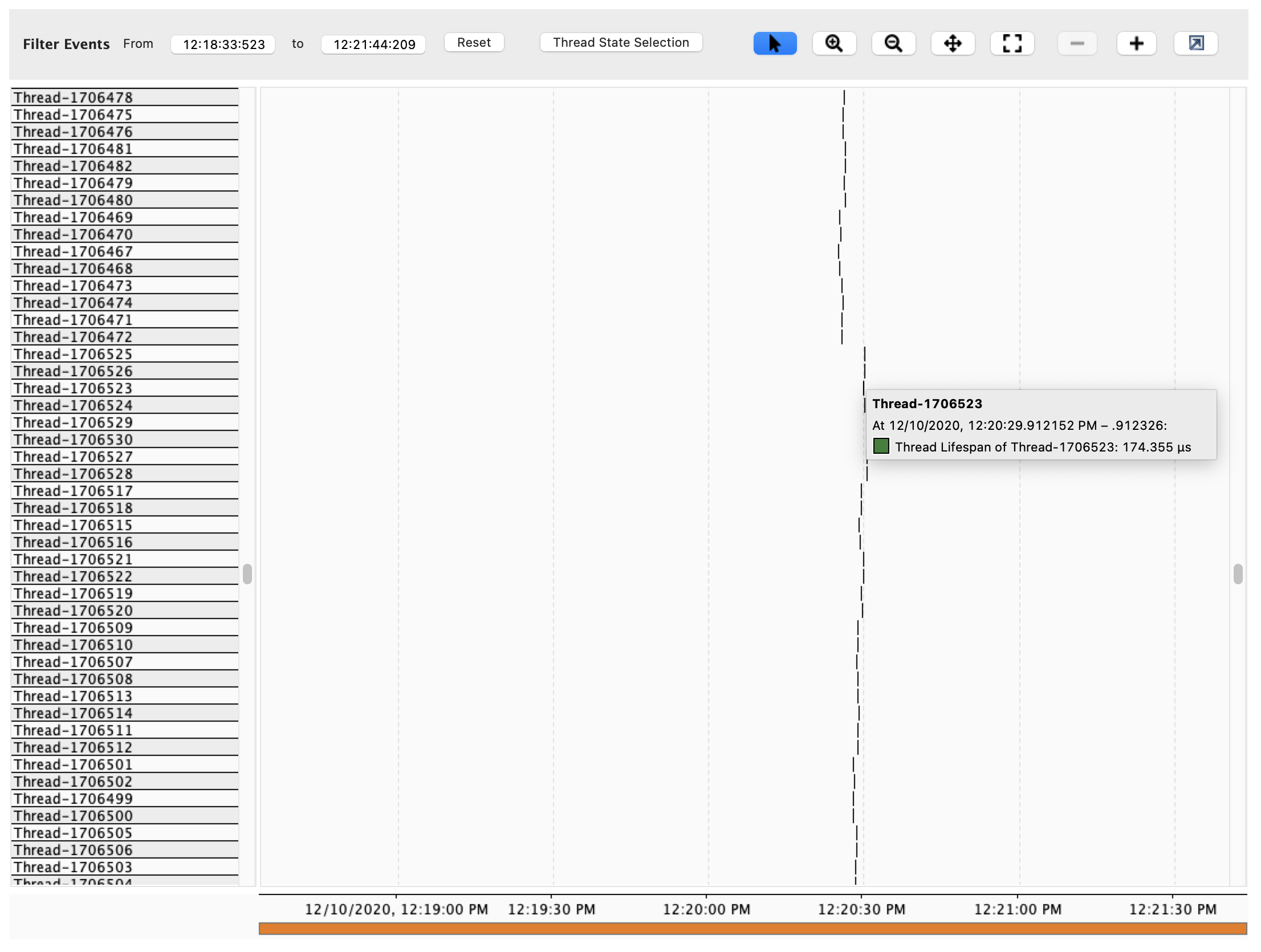
However, when looking at the Java Thread Start or the Java Thread End events there is no stack trace. Fortunately these short-lived thread created objects, which triggered the Allocation in new TLAB events.
As a reminder the generational GCs in the JVM dedicate a space of the Eden memory (where objects are created) for each thread, when these new threads are created they require a new TLAB for their new objects.
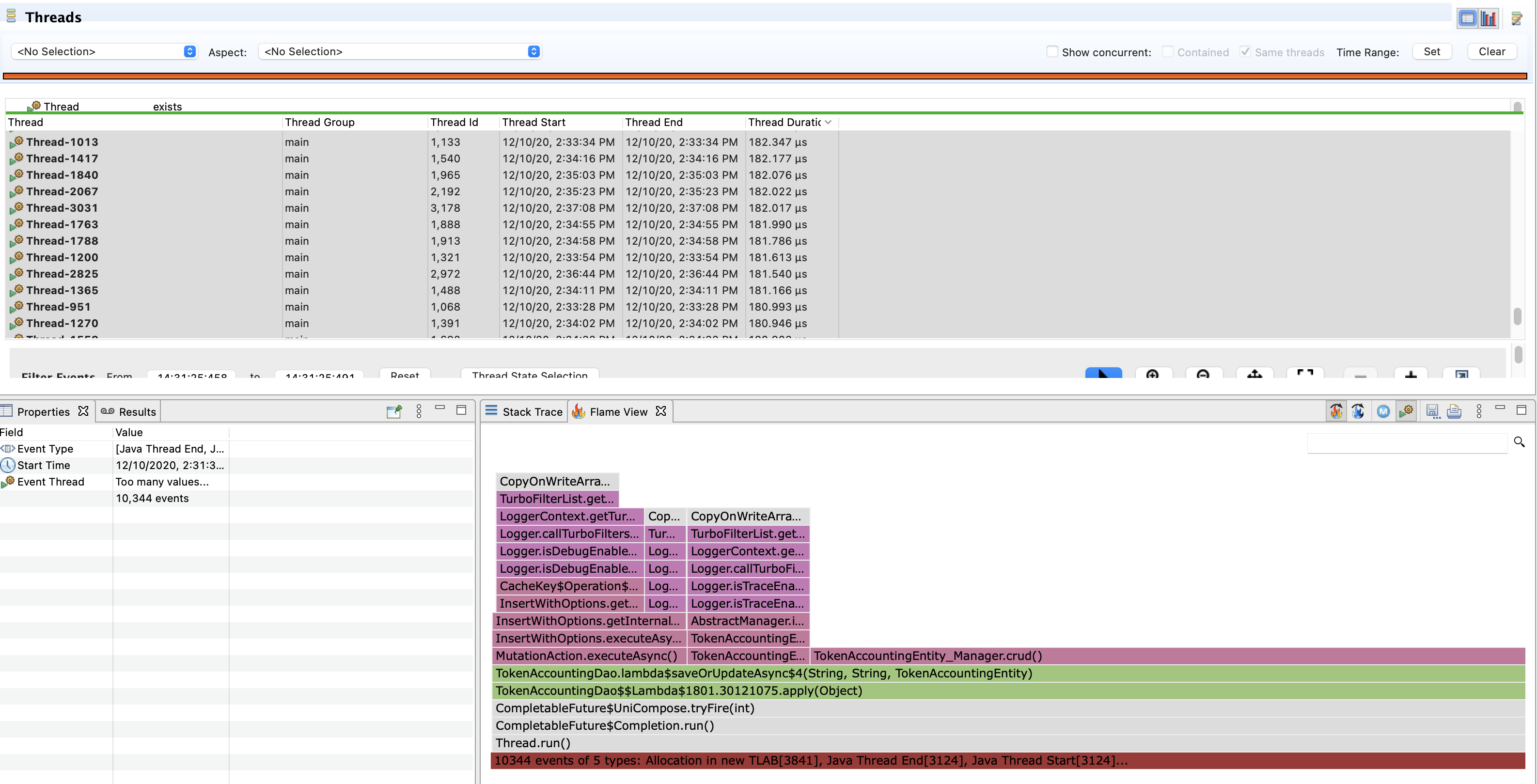
Now that I know what those threads are executing it will be easier to follow the trail to where these threads get created.
public CompletableFuture<Empty> saveOrUpdateAsync(String a, String b) {
return tryFindAsync(userId, clientId)
.thenApply(t -> ...)
.thenComposeAsync(
t -> manager.crud() (1)
.insert(t) (1)
.withLwtResultListener(error -> ...)) (1)
.executeAsync()); (1)
}| 1 | This code shows up the allocation event |
I’m usually avoiding CompletableFuture for asynchronous tasks as I find their API
bulky and ambiguous and I remember that they ship with some
surprises.
That’s a personal opinion I know. Yet it’s not unusual to find
them used in a framework to avoid external dependencies.
As I don’t use them, I wondered CFs don’t create a new Thread for fun, right ?
It turns out it’s possible with the right conditions ! Let’s hit back the trail
in the CompletableFuture code with the method thenComposeAsync:
public <U> CompletableFuture<U> thenComposeAsync(
Function<? super T, ? extends CompletionStage<U>> fn) {
return uniComposeStage(defaultExecutor(), fn); (1)
}This method uses the default CompletableFuture pool.
Note the Javadoc of this method is located on CompletionStage.thenComposeAsync,
and does not say anything useful regarding threads.
/**
* Returns the default Executor used for async methods that do not
* specify an Executor. This class uses the {@link
* ForkJoinPool#commonPool()} if it supports more than one (1)
* parallel thread, or else an Executor using one thread per async
* task. This method may be overridden in subclasses to return
* an Executor that provides at least one independent thread.
*
* @return the executor
* @since 9
*/
public Executor defaultExecutor() {
return ASYNC_POOL;
}| 1 | There it is: if ForkJoinPool#commonPool() parallelism
is 1, then a single thread will be created per task. |
In particular the code looks like this:
private static final boolean USE_COMMON_POOL =
(ForkJoinPool.getCommonPoolParallelism() > 1);
/**
* Default executor -- ForkJoinPool.commonPool() unless it cannot
* support parallelism.
*/
private static final Executor ASYNC_POOL = USE_COMMON_POOL ?
ForkJoinPool.commonPool() : new ThreadPerTaskExecutor();
/** Fallback if ForkJoinPool.commonPool() cannot support parallelism */
static final class ThreadPerTaskExecutor implements Executor {
public void execute(Runnable r) { new Thread(r).start(); }
}Also in my experience I didn’t use much the ForkJoinPoll, but I remember
there was some pool criticism when used Collection.parallelStream() about
pool sizing. This is exactly the case here since this API of CompletableFuture
rely on the default.
This is likely to have been mentioned by other bloggers that are using the JVM
in containers. If ForkJoinPool does not see more than one processor, then
CompletableFuture will use a new Thread for each task. Let’s see what the
defaults.
$ env -u JDK_JAVA_OPTIONS jshell -s - \
<<<'System.out.printf("fjp-parallelism: %d%n", java.util.concurrent.ForkJoinPool.getCommonPoolParallelism())'
fjp-parallelism: 1In my case the container resources is configured to 2 cpu in the Kubernetes deployment descriptor :
resources:
limits:
memory: "5.5Gi"
requests:
cpu: 2 (1)
memory: "5.5Gi"| 1 |
You can check the cgroup too if it’s not a kubernetes deployment :
$ cat /sys/fs/cgroup/cpu/cpu.shares
2048It’s always possible to check what the runtime sees (since the JVM understand cgroup (v1)):
$ env -u JDK_JAVA_OPTIONS jshell -s - \
<<<'System.out.printf("procs: %d%n", Runtime.getRuntime().availableProcessors())'
procs: 2Here’s how ForkJoinPool is coded to configure the parallelism:
/**
* Returns the targeted parallelism level of the common pool.
*
* @return the targeted parallelism level of the common pool
* @since 1.8
*/
public static int getCommonPoolParallelism() {
return COMMON_PARALLELISM;
}
static {
// ...
common = AccessController.doPrivileged(new PrivilegedAction<>() {
public ForkJoinPool run() {
return new ForkJoinPool((byte)0); }});
COMMON_PARALLELISM = Math.max(common.mode & SMASK, 1);
}
/**
* Constructor for common pool using parameters possibly
* overridden by system properties
*/
private ForkJoinPool(byte forCommonPoolOnly) {
int parallelism = -1;
// ...
try { // ignore exceptions in accessing/parsing properties
String pp = System.getProperty
("java.util.concurrent.ForkJoinPool.common.parallelism");
if (pp != null)
parallelism = Integer.parseInt(pp);
// ...
} catch (Exception ignore) {
}
// ...
if (parallelism < 0 && // default 1 less than #cores
(parallelism = Runtime.getRuntime().availableProcessors() - 1) <= 0) (1)
parallelism = 1; (1)
if (parallelism > MAX_CAP)
parallelism = MAX_CAP;
// ...
this.mode = parallelism;
// ...
}| 1 | Indeed, FJP subtract one to the reported available processors. |
The constructor also initializes a lot of things, in particular the Thread factory, the pool boundaries, the work queues, etc. Also, we see the few properties that are looked up to override the defaults.
In particular the parallelism value can be overridden by java.util.concurrent.ForkJoinPool.common.parallelism
as stated in the
javadoc
and in the constructor code.
Back to the main issue, there are two ways to fix this, either change the code to pass an executor, or tell default pool what is the system parallelism. Both are options are not mutually exclusive, and it’s always possible that some code that use the common ForkJoinPool.
$ env JDK_JAVA_OPTIONS="-Djava.util.concurrent.ForkJoinPool.common.parallelism=3" \
jshell -s - \
<<<'System.out.printf("fjp-parallelism: %d%n", java.util.concurrent.ForkJoinPool.getCommonPoolParallelism())'
fjp-parallelism: 3I changed this value with care the short task are really short, and they are not too many, hence the low value of 3. Also, this does work because the containers are not limited in CPU, so they won’t be throttled which would have been very bad for a runtime like the JVM.
CPU shares and CPU quotas
In Kubernetes, the CPU resources have different meaning in the cgroup:
-
requests are configured as CPU shares,
-
and the limits are configured as CPU Quotas (hence the term milli-cpu or milli-core).
CPU shares
When making a pod burstable in Kubernetes, the CPU limit is not set.
resources:
limits:
memory: "5.5Gi"
requests:
cpu: 2 (1)
memory: "5.5Gi"| 1 | This number means there will be 2048 (2 x 1024) CPU shares. |
$ cat /sys/fs/cgroup/cpu/cpu.shares
2048The JVM will use CPU shares when no quota are defined.
Beware when the cpu request is 1, the cpu shares of the cgroup will be 1024,
and as it happens the CPU share of a cgroup is also 1024, in this case the JVM
do not know if a cpu share has been set or not for this cgroup (
source),
which means it will not use this value and instead use the number of processors
of the host machine.
CPU quotas
Kubernetes set the CPU limit as a CPU quota. CPU quota are used by the Linux Completely Fair Scheduler to limit the process usage of a CPU when in a cgroup.
| Setting quotas may throttle your process and may result in disastrous responsiveness. I believe the current best practice is to set the CPU request to help Kubernetes schedule the pod on the available hardware, but let the process burst if more CPU is required for a brief time, like during a GC. |
The JVM will use the quota in combination of the period (it is not currently configurable in a Kubernetes deployment descriptor).
resources:
limits:
cpu: 3 (1)
memory: "5.5Gi"
requests:
cpu: 2
memory: "5.5Gi"| 1 | 3 means a quota of 300000 or 3 x 100000, which 3 times the default period (100ms),
the docker arguments would then be either --cpus=3 or --cpu-quota=300000 |
If a CFS quota is in place then it’s possible to know their parameters by looking
at the cgroup values. The below values are equivalent to --cpus=3 or
--cpu-quota=300000 assuming the period is the default one (100000).
$ cat /sys/fs/cgroup/cpu/cpu.cfs_period_us
100000
$ cat /sys/fs/cgroup/cpu/cpu.cfs_quota_us
300000If you are caught with throttled process, then it’s possible to
see it via the cpu.stat special file.
$ cat /sys/fs/cgroup/cpu/cpu.stat
nr_periods 0
nr_throttled 0
throttled_time 0Tell the JVM to prefer CPU shares
If you are adventurous it’s possible to tell the JVM to lookup the CPU shares instead
of the CPU quota with -XX:-PreferContainerQuotaForCPUCount (it is true by default).
|
Calculate the container CPU availability based on the value of quotas (if set), when true. Otherwise, use the CPU shares value, provided it is less than quota. When cpu share is 1024, the quota will be used as well. |
The above is unlikely to be useful in the real world, but who knows.
End words
Again, containers narrower walls, tricks the JVM to choose inadequate defaults (or runtime ergonomics) for their workload.