
Off-Heap memory reconnaissance
This entry has been marinating for most of the year 2020. Rewriting it multiple times to make it more digestible form, I’ve left out some content, but this is still a big piece to read.
Motivation
I have been running applications in containers for a while now, and I have noted that this shift in deployment resulted in tighter constraints. And the closer the walls are the more we, software developers (or anyone involved in production), should pay attention to how memory is consumed.
Indeed, sometime getting the right memory limit for Java applications is sometimes an
intangible task, and I think the
MaxRAMPercentage flag is certainly not the right tool for this job.
Moreover, with a given limit, if an application gets OOM Killed then one has to ask if it is the limit that needs adjustment or if it is the application that is misbehaving (memory leak in particular, but not always).
To answer questions about memory usage there are various things to look at, Java Heap, Metaspace other JVM components, etc. I faced a few incidents, where the JVM settings and the Kubernetes memory limit were seemingly appropriate, yet the apps were constantly OOM Killed because the RSS kept growing toward this limit. Some of these issues have been solved just by raising the memory limit. However, in some other cases it wasn’t that crystal clear.
This served as excuse to go down the rabbit hole.
This entry will hopefully help to understand the basics of how a
java process uses native memory and remind some rudiments of OS
memory management.
|
Most of the time, figures will use the IEC binary notation ( Some charts may however use the SI metric notation ( Actually, 227,893 KB is only 222 MB. For ease of discussion, I’ll truncate the KBs part by 1,000 in this chapter; pretend I’m a disk manufacturer.
— Java Performance: The Definitive Guide
Getting the Most Out of Your Code (1st Edition) Thanks to this tweet. |
| Also, all java snippet and command have been run with Java 11. |
| Last one, this writing assume the cgroups v1, the v2 have slight variation that I haven’t studied yet. |
Getting comfortable with the memory of a (JVM) process is a tedious task for most of us that wrote code in Java for their entire professional life. However, this is a rewarding task, and it’s possible to extract useful findings.
Exploration begins
The JVM flags as a starting point
When assessing java memory, one of the fist thing to look at are the Java heap parameters.
It’s likely anyone that reads this article is familiar with Xms or Xmx, but there are
other ways to define the boundaries of the Java heap in particular if the process is started
with \*RAMPercentage. With these the JVM will compute the actual values from the cgroup,
in this case it’s possible to access the actual runtime values with jcmd.
In short, it’s possible to look at the command line options, but using the diagnostic
command jcmd {pid} VM.flags lets you peek at the actual values that the JVM used.
For example with a memory limit of 5 GiB, if a process is started with
-XX:InitialRAMPercentage=85.0 -XX:MaxRAMPercentage=85.0 the VM.flags
diagnostic command will output this :
$ jcmd $(pidof java) VM.flags | tr ' ' '\n'
6:
...
-XX:InitialHeapSize=4563402752 (3)
-XX:InitialRAMPercentage=85.000000 (1)
-XX:MarkStackSize=4194304
-XX:MaxHeapSize=4563402752 (4)
-XX:MaxNewSize=2736783360
-XX:MaxRAMPercentage=85.000000 (2)
-XX:MinHeapDeltaBytes=2097152
-XX:NativeMemoryTracking=summary
...| 1 | Initial RAM at 85% |
| 2 | Max RAM at 85% |
| 3 | Initial heap size ~4.25 GiB |
| 4 | Max heap size ~4.25 GiB |
Do not confuse the VM.flags command which will output parameters calculated from the
command line and VM.command_line which will print the raw command line.
|
The other Hotspot flag values comes are JVM defaults, which may either be static values, or computed from internal heuristics.
As we tend to dismiss regularly, the Java heap is only a part of the process memory usage. So now let’s dig into how memory is consumed. The values or snippet comes from an application running inside a container.
The real memory footprint of the java process in the container
The JVM is doing everything to keep software developers from caring about memory, and before containers the bigger systems helped to sustain this comfortable way of programming. Sometime there’s a Java heap memory leak but it doesn’t happen every day, and even more remotely there’s a problem with the process memory.
There’s more chance we could get hit by GC pauses.
With containers, one of the most critical things to look at is the resident set size,
that’s the native memory, it can be obtained in various ways, using ps, top or
reading the /proc filesystem. E.g. on the same application on which
I got the flags above:
ps$ ps o pid,rss -p $(pidof java)
PID RSS
6 4701120/proc/{pid}/status$ cat /proc/$(pgrep java)/status | grep VmRSS
VmRSS: 4701120 kBThe reported RSS of the process is 4.6 GiB, and its configured Java heap size
is 4.25 GiB, this lead to think this process uses around 0.35 GiB of
non-Java heap memory, I’ll refer to this part of the memory as native memory.
Note the rest of article will dig into how to understand these numbers.
I’d like to dig a bit to understand the reported number 4701120 KiB,
what it actually measures.
The JVM component memory
In order to understand how the Java process memory is consumed, we need to use
Native Memory Tracking (-XX:NativeMemoryTracking=summary) which produces
an overview of the memory usage by the components of the JVM. It actually gives
a pretty good picture of the "cost" of having a JVM.
|
Enabling detailed native memory tracking (NMT) causes a 5% to 10% performance overhead. The summary mode merely has an impact in memory usage as shown below and is usually enough. Thanks to a question from Juraj Martinka for his comments, and his Stackoverflow question about overhead of Java NativeMemoryTracking. Having an idea of the overhead of the different mode is nice, but I found the answer of Thomas Stuefe, very satisfying:
|
It is necessary to note that while the above command indicate a scale
in KB for the JVM it really means KiB (the power of 2 unit).
|
$ jcmd $(pidof java) VM.native_memory
6:
Native Memory Tracking:
Total: reserved=7168324KB, committed=5380868KB (1)
- Java Heap (reserved=4456448KB, committed=4456448KB) (2)
(mmap: reserved=4456448KB, committed=4456448KB)
- Class (reserved=1195628KB, committed=165788KB) (3)
(classes #28431) (4)
( instance classes #26792, array classes #1639)
(malloc=5740KB #87822)
(mmap: reserved=1189888KB, committed=160048KB)
( Metadata: )
( reserved=141312KB, committed=139876KB)
( used=135945KB)
( free=3931KB)
( waste=0KB =0.00%)
( Class space:)
( reserved=1048576KB, committed=20172KB)
( used=17864KB)
( free=2308KB)
( waste=0KB =0.00%)
- Thread (reserved=696395KB, committed=85455KB)
(thread #674)
(stack: reserved=692812KB, committed=81872KB) (5)
(malloc=2432KB #4046)
(arena=1150KB #1347)
- Code (reserved=251877KB, committed=105201KB) (6)
(malloc=4189KB #11718)
(mmap: reserved=247688KB, committed=101012KB)
- GC (reserved=230739KB, committed=230739KB) (7)
(malloc=32031KB #63631)
(mmap: reserved=198708KB, committed=198708KB)
- Compiler (reserved=5914KB, committed=5914KB) (8)
(malloc=6143KB #3281)
(arena=180KB #5)
- Internal (reserved=24460KB, committed=24460KB) (10)
(malloc=24460KB #13140)
- Other (reserved=267034KB, committed=267034KB) (11)
(malloc=267034KB #631)
- Symbol (reserved=28915KB, committed=28915KB) (9)
(malloc=25423KB #330973)
(arena=3492KB #1)
- Native Memory Tracking (reserved=8433KB, committed=8433KB)
(malloc=117KB #1498)
(tracking overhead=8316KB)
- Arena Chunk (reserved=217KB, committed=217KB)
(malloc=217KB)
- Logging (reserved=7KB, committed=7KB)
(malloc=7KB #266)
- Arguments (reserved=19KB, committed=19KB)
(malloc=19KB #521)
- Module (reserved=1362KB, committed=1362KB)
(malloc=1362KB #6320)
- Synchronizer (reserved=837KB, committed=837KB)
(malloc=837KB #6877)
- Safepoint (reserved=8KB, committed=8KB)
(mmap: reserved=8KB, committed=8KB)
- Unknown (reserved=32KB, committed=32KB)
(mmap: reserved=32KB, committed=32KB)| 1 | This shows a reserved value (7168324 KiB (~6.84 GiB)), it’s the amount
of addressable memory on that container, and a committed value (4456448 KiB (~4.25 GiB))
that represents what the JVM actually asked the OS to allocate. |
| 2 | Heap zone, note that reserved and committed values are the same 4456448 KiB
here because our InitialRAMPercentage is the same as max. I’m not sure why this number
is different from the VM flags -XX:MaxHeapSize=4563402752 though. |
| 3 | ~162 MiB of metaspace. |
| 4 | How many classes have been loaded : 28431. |
| 5 | There are 674 threads whose stacks are using ~80 MiB at this time. |
| 6 | Code cache area (assembly of the used methods) ~102 MiB out of ~246 MiB. |
| 7 | This section contains GC algorithms internal data structures, this is app
is using G1GC which takes ~225 MiB. |
| 8 | C1 / C2 compilers (which compile bytecode to assembly) use ~5.8 MiB. |
| 9 | The Symbol section contains many things like interned strings and other
internal constants for about 28.2 MiB. |
| 10 | The Internal area takes ~24 MiB. Before Java 11 this area included
DirectByteBuffers, but from Java 11 those are accounted in the Other zone. |
| 11 | The Other section after Java 11 includes DirectByteBuffers ~261 MiB. |
The remaining areas are much smaller in scale, NMT takes ~8.2 MiB
itself, module system usage ~1.3 MiB, etc. Also, note that enabling
other JVM features may show up if they are activated, like flight recorder.
Source
There’s a lot more to read on the official documentation about NMT and how to Monitor VM Internal Memory. Yet another worthwhile read on native memory tracking by Aleksey Shipilёv.
In the rest of this article when talking the context of Native Memory Tracking I may use the terms memory type or memory zones, but the real definition would be :
the memory allocation type performed by a JVM component
The different sections are defined there in
this MemoryType enumeration,
and here
as they appear in the report.
NMT is a great tool to gain an insight on the memory usage of the various
parts that compose the Java runtime. It has interesting subcommands to compare
the memory usage of the JVM components with a baseline
(jcmd $(pidof java) VM.native_memory baseline, followed at some point by
one or several jcmd $(pidof java) VM.native_memory summary.diff).
This is very useful for JVM components and a good complement to what I would
like to show in this article, because NMT alone does not answer
what is actually accounted in the RSS column of ps.
Revising OS virtual memory and memory management
I mentioned this acronym already, RSS or Resident Set Size, what is it? What exactly means committed memory or reserved memory reported in NMT ? How do they relate to each other?
First let’s break down the vocabulary when we talk about memory.
Committed |
Address ranges that have been mapped or |
Reserved |
The total address range that has been pre-mapped via |
Resident |
OS memory pages which are currently in physical ram. This means
code, stacks, part of the committed memory pools but also portions of |
Virtual |
The sum of all virtual address mappings. Covers committed, reserved memory pools but also mapped files or shared memory. This number is rarely informative since the JVM will reserve large address ranges upfront. We can see this number as the pessimistic memory usage. |
The above graph mostly displays the relative size by memory kind within the address space of a process. In order to explain resident memory it’s necessary to revise how Linux (and other OSes by the way) manage memory using the concept of paging.
The virtual address space is divided into smaller chunks called pages
usually of 4 KiB.
There are other page sizes and these sizes may even co-exist (e.g. having pages of
4 KiB mixed with 2 MiB pages), it depends on the capabilities
of the processor ; working with different size of pages is something that is out
of scope for this article.
What is interesting is how paging and RSS relate to each other.
The graph above shows the addressable space of a process and its pages. The process can access these pages using the addresses of its virtual space, however these pages have to be stored physically, usually in RAM, sometime on disk. When referring to these chunks of memory on hardware, we use the term frame.
The real memory address is naturally different from this virtual address space for the process. In the CPU there’s a specialized component called MMU (Memory Management Unit) whose role is to translate the virtual addresses to physical addresses.
The incentive behind virtual memory and paging comes from multi-tasking, it allows running multiple program concurrently. Each process will have the illusion of a single big block of memory. In practice, it abstracts away useful tricks like lazy allocation, swapping, file mapping, defragmentation, caching, etc.
The OS is hard at work performing these tricks while keeping this illusion for all processes. Since programs run concurrently, not all memory pages is used at the same time.
In practical terms we can observe that:
-
A physical memory frame won’t be used if the process didn’t touch a page, or we can say this page doesn’t exist.
-
The kernel may choose to move the content of a page to a slower device, usually a disk in a special place called swap if it thinks there won’t be enough physical memory (RAM).
-
The kernel may use unemployed physical frames for caching purpose, or other tasks like defragmentation.
The resident set size mean the total set of pages of a process, i.e. without untouched / unused pages. This contrasts with virtual size which includes the total address space of a program, this value is usually way superior to RSS.
If you want to dive how the whole paging thing works head to system courses, or articles (like this masterpiece) where they usually explain in depth how everything interacts.
Reserved and committed memory for NMT
Concretely for the JVM it means that
-
the committed memory is immediately usable,
-
and the reserved memory part means memory put on hold and not immediately usable.
With a better understanding of how memory works let’s look again at the output
of the VM.native_memory command to make more sense of it:
Total: reserved=7168324KB, committed=5380868KB (1)
- Java Heap (reserved=4456448KB, committed=4456448KB) (2)
(mmap: reserved=4456448KB, committed=4456448KB)
...
- Class (reserved=1195628KB, committed=165788KB) (3)
...
- Thread (reserved=696395KB, committed=85455KB) (4)
...
- Code (reserved=251877KB, committed=105201KB)
...
- GC (reserved=230739KB, committed=230739KB) (5)
...| 1 | The process addressable memory and what is currently committed. |
| 2 | Here the NMT also show the same abstractions of committed and reserved memory,
on this process these values are the same because the InitialHeapSize (Xms) and
MaxHeapSize (Xmx)are the same. If these boundaries were different it is likely
the heap zone would show different values for reserved and committed memory; the
JVM will increase the committed memory if necessary, and can even uncommit some of
this memory if the GC algorithm allows it. |
| 3 | Class, Code spaces works the same way, specifics JVM flags control the reserved and committed memory. |
| 4 | Java Threads are allocated within the process memory, the JVM flags only control the size of a thread. I will expand on this later. |
| 5 | Then comes the other memory space of the JVM, like the GC internal structures, who are using a different memory management, these zones usually have the same reserved/committed amount. |
Or with a picture :
This graph bring the following definitions :
Used Heap |
The amount of memory occupied by live objects and to a certain extent object that are unreachable but not yet collected by the GC. This only relate to the JVM Java heap. |
Committed heap |
The current limit if the writable memory to write objects to.
It’s the current workspace of the GC. Upon JVM bootstrap this value should be equal
to |
Heap Max Size |
The maximum amount of memory that the Java heap can occupy.
It’s the reserved amount in Java Heap section of the NMT output.
If the application requires more memory, this will result in a |
So committed stands for writable memory and, reserved stands for total addressable space of the memory. How does it work concretely?
The JVM starts by reserving the memory,
then parts of this "reserve" will be made available by
modifying the memory mappings
using malloc, mmap, as well as mprotect calls in particular (on Linux).
malloc and mmap
The malloc and mmap C calls ask the OS to allocate memory. The OS will then
provide the application the necessary memory or report an error if it is not possible.
Also, depending on the mapping in particular for mmap the OS can be asked
to make a file accessible as a memory zone, in short it’s the kernel that perform
IOs, in contrast to perform IOs with a file descriptor application side.

Differences between malloc and mmap
-
mallocmay recycle previously used memory that was released byfree, and perform a system call to get memory only required. It’s part of the C standard. -
mallocallows you pass a size and that’s basically it. -
mmapis a system call. It’s not part of the C standard, and may not be available on all platforms. -
mmapcan both map private memory or shared memory (as in shared with other processes). Those are called anonymous mapping using flagMAP_ANONYMOUS. -
mmapcan also interact with disk files on specific ranges, without having a file descriptor. -
mmapcan be set with various flags that are used to control how this memory mapping behave. -
Both have their performance characteristics,
mallocis usually preferred for few and small allocations,mmapis preferred for few but large allocations.
When the JVM bootstrap, it requests a main memory of a certain size with the PROT_NONE
flag to prevent any access. This has the effect to tell the OS that this mapping should
not be backed by physical memory. Then when memory is needed by the program,
the JVM changes the mapping for a sub-range of that main memory by removing the
PROT_NONE flag. When new java threads are created, then the JVM will simply
request another memory segment.
Simple C code example
To help you understand here’s a very simple program:
-
that reserves
16 MiBvia amalloccall and16 MiBvia themmapcall -
then this program will invoke
psto show its actual memory consumption (RSS) -
then it will touch/use memory by setting a bit every
1 KiB -
then this program will invoke
psagain to show its actual memory consumption (RSS)
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/mman.h>
#define HEAP_SIZE (16 * 1024 * 1024 * sizeof(char))
int main (int argc, char *argv[])
{
char *heap1 = malloc(HEAP_SIZE);
char *heap2 = mmap(0,
HEAP_SIZE,
PROT_NONE | PROT_WRITE,
MAP_PRIVATE | MAP_NORESERVE | MAP_ANONYMOUS,
-1,
0);
pid_t pid = getpid();
printf("pid: %d\n", pid);
char buffer[50];
sprintf(buffer, "ps -p %d -o rss,vsz,command", pid);
printf("Executing: '%s'\n", buffer);
system(buffer);
printf("Writing to some pages, but not all\n");
for (char* i = heap1; i < (heap1 + HEAP_SIZE / 16); i += 1024) {
*i = 0x01;
}
for (char* i = heap2; i < (heap2 + HEAP_SIZE / 8); i += 1024) {
*i = 0x01;
}
sprintf(buffer, "ps -p %d -o rss,vsz,command", pid);
printf("Executing: '%s'\n", buffer);
system(buffer);
free(heap1);
munmap(heap2, HEAP_SIZE);
return 0;
}$ clang -Wall -Wpedantic -o test-alloc test-alloc.c && ./test-alloc
pid: 4301956
Executing: 'ps -p 2904 -o rss,vsz,command'
RSS VSZ COMMAND
708 4301956 ./test-mem
Writing to some pages, but not all
Executing: 'ps -p 2904 -o rss,vsz,command'
RSS VSZ COMMAND
3780 4301956 ./test-memAs the stdout shows the RSS of this program is very low until memory
is actually written to. At the same time the virtual memory is much,
much higher; it means this simple program could address up to
about 4 GiB.
This program ran on a MacBook Pro 2018 running an Intel Core i7 CPU.
Now after some memory management refresh, let’s go back to the main topic of this blog post.
Exploring what NMT does not show
The previous section walked through the numbers reported, and that they represent the sizes of the different JVM memory zones, but, does not reveal the effective usage.
The JVM components can use different types of memory management and as such may have multiple allocation mechanisms. NMT reports the different allocation types, for example:
-
GC based The
Java heapand theMetaspace(Class) are usually the biggest consumers of memory, they both rely onmmap.Java heap and metaspace- Java Heap (reserved=3145728KB, committed=3145728KB) (mmap: reserved=3145728KB, committed=3145728KB) - Class (reserved=1195111KB, committed=164967KB) (classes #27354) ( instance classes #25689, array classes #1665) (malloc=5223KB #86596) (mmap: reserved=1189888KB, committed=159744KB)These two memory zones are interesting in that they are managed by the GC algorithm, put in other words the GC is actually the memory manager of these zones, it is able to arrange the memory according to the options that are passed on the command line. E.g. with a fixed size heap (
Xms=Xmx), the heap will be constituted of a large memory segment, in this case the reserved and committed values will be the same as well.Other options may trigger specific behavior for these memory zones, e.g. make the heap to grow or to shrink (I never saw that in practice, maybe I’ll see it once I use a JDK 12+ with heap uncommit with JEP-346, although even the JEP mention it’ll only happen if there is very low activity, which is unlikely to happen for some workload).
-
Threads The Java threads are constructs controlled by the JVM runtime, each thread is allocated on addressable space, their allocation size is always the same, but can be controlled via a few JVM parameters. Their usage depends on application usage. E.g. if the program request 1000 threads, then the JVM needs to allocate 1000 threads.
Thread- Thread (reserved=533903KB, committed=70439KB) (thread #517) (stack: reserved=531432KB, committed=67968KB) (1) (malloc=1866KB #3103) (2) (arena=605KB #1033) (3)1 The stack memory is where the JVM puts the thread stack, it’s the sum of all thread stack memory mappings. 2 The thread sub-system performed 3103 malloccalls amounting to1866 KiB.3 The thread local handles required 1033 arenas, amounting to 605 KiB. -
Other native zones The other component reported by NMT management uses different technics. Sometime using a combination of these technics:
GCzone for example only works withmallocandmmap, and size can grow as needed.GC- GC (reserved=180505KB, committed=180505KB) (malloc=30589KB #219593) (1) (mmap: reserved=149916KB, committed=149916KB) (2)1 Here the GC performed 219593 malloccalls amounting to30589 KiB.2 Here the GC reserved and committed memory segment(s) amount to 149916 KiB.The JVM also implements its own Arena based memory management, (distinct from the arena memory management of glibc). It is used by some subsystems of the JVM or when native code uses internal objects that rely on JVM arenas [1] [2]
Compiler,Symbol tabledo use this memory management for example. Special mention of the thread local handles that also use JVM arenas.NMT reports all the memory allocation technics that are used by a JVM component, for example the GC system :
compiler- Compiler (reserved=6666KB, committed=6666KB) (malloc=6533KB #3575) (3) (arena=133KB #5) (4)3 The compiler performed 3575 malloccalls amounting to6533 KiB.4 The compiler uses 5 arenas totaling 133 KiB.
Track DirectByteBuffer with NMT
Using NMT baseline and summary.diff modes, it is possible to
track the evolution of the JVM components. DirectByteBuffers
allow allocating native memory segments. They are not cheap to create,
and they are only deallocated when a GC actually finalize the
references. Usually these byte buffers have a long life and
they are big.
The following snippet of code will try to show they are reported in the
Other section of NMT. Note that in this snippet I’m just invoking
the external process jcmd for brevity and clarity, but it’s possible
to invoke the diagnostic command in pure Java.
DirectByteBuffer and NMT// env -u JDK_JAVA_OPTIONS java -XX:NativeMemoryTracking=summary DBB.java 1 1
import java.nio.*;
import java.lang.ProcessBuilder.*;
public class DBB {
public static void main(String[] args) throws Exception {
System.out.printf("nmt baseline: %n");
new ProcessBuilder("jcmd", Long.toString(ProcessHandle.current().pid()), "VM.native_memory", "baseline")
.redirectOutput(Redirect.INHERIT)
.redirectError(Redirect.INHERIT)
.start()
.waitFor();
var bbCount = Integer.parseInt(args[0]);
var bbSizeMiB = Integer.parseInt(args[1]);
for (var i = 0; i < bbCount; i++) {
var byteBuffer = ByteBuffer.allocateDirect(bbSizeMiB * 1024 * 1024)
.putInt(0, 0x01);
}
System.out.printf("nmt summary.diff: %n");
new ProcessBuilder("jcmd", Long.toString(ProcessHandle.current().pid()), "VM.native_memory", "summary.diff")
.redirectOutput(Redirect.INHERIT)
.redirectError(Redirect.INHERIT)
.start()
.waitFor();
}
}$ env -u JDK_JAVA_OPTIONS java -XX:NativeMemoryTracking=summary DBB.java 1 1
nmt baseline:
779:
Baseline succeeded
nmt summary.diff:
779:
Native Memory Tracking:
Total: reserved=1916470KB +1027KB, committed=113950KB +1031KB
- Java Heap (reserved=509952KB, committed=32768KB)
(mmap: reserved=509952KB, committed=32768KB)
...
- Other (reserved=1034KB +1024KB, committed=1034KB +1024KB) (1)
(malloc=1034KB +1024KB #3 +1) (2)
...| 1 | The DirectByteBuffer of 1 MiB. |
| 2 | DirectByteBuffers use malloc underneath. |
$ env -u JDK_JAVA_OPTIONS java -XX:NativeMemoryTracking=summary DBB.java 10 1
nmt baseline:
839:
Baseline succeeded
nmt summary.diff:
839:
Native Memory Tracking:
Total: reserved=1933553KB +10243KB, committed=132061KB +10247KB
- Java Heap (reserved=509952KB, committed=32768KB)
(mmap: reserved=509952KB, committed=32768KB)
...
- Other (reserved=10250KB +10240KB, committed=10250KB +10240KB) (1)
(malloc=10250KB +10240KB #12 +10) (2)
...| 1 | The 10 DirectByteBuffers of 1 MiB. |
| 2 | DirectByteBuffers use malloc underneath. |
$ env -u JDK_JAVA_OPTIONS java -XX:NativeMemoryTracking=summary DBB.java 20 100
nmt baseline:
898:
Baseline succeeded
nmt summary.diff:
898:
Native Memory Tracking:
Total: reserved=2331899KB +408590KB, committed=512275KB +390462KB
Total: reserved=2323817KB +409608KB, committed=498961KB +386252KB
- Java Heap (reserved=509952KB, committed=10240KB -22528KB) (3)
(mmap: reserved=509952KB, committed=10240KB -22528KB)
...
- Other (reserved=409610KB +409600KB, committed=409610KB +409600KB) (1)
(malloc=409610KB +409600KB #6 +4) (2)
...| 1 | The 20 DirectByteBuffers of 100 MiB. Uh wait, 409600 KiB is nothing near ~2 GiB (2048000 KiB),
it looks more like 4 buffers of 100 MiB |
| 2 | DirectByteBuffers use malloc underneath. |
| 3 | This times there is also a reduction in the Java Heap. |
As one can see the total reserved and committed memory are actually increased by the amount of allocated memory.
The last exercise, 20 x 100 MiB, is more captivating: the low amount of
allocated memory by DirectByteBuffers is simply explained by the GC
that kicked in, if run the last command with -Xlog:gc* you’ll notice 4 Full GC
happening in the middle of the loop.
[1.671s][info][gc,start ] GC(4) Pause Full (System.gc())The above code don’t keep strong references to the wrapping buffers,
thus allowing these object to be GCed, if the references of these
byte buffers were kept, this program would exited with a
java.lang.OutOfMemoryError: Direct buffer memory
It’s not part of this article but it’s well worth to understand
how DirectByteBuffers handle their garbage collection (using a
Cleaner).
Now I mentioned that there was 4 Full GCs, that should have raised eyebrows.
If it didn’t the full GC cause should provoke the attention, System.gc().
Pretending I don’t know where this came from I’ll search where these are happening
$ env -u JDK_JAVA_OPTIONS java -XX:NativeMemoryTracking=summary \
-agentpath:async-profiler-1.8.2-linux-x64/build/libasyncProfiler.so=start,event=java.lang.System.gc,traces,file=traces.txt \
DBB.java 20 100 > /dev/null 2>&1
$ cat traces.txt
--- Execution profile ---
Total samples : 4
Frame buffer usage : 0.0012%
--- 4 calls (100.00%), 4 samples
[ 0] java.lang.System.gc
[ 1] java.nio.Bits.reserveMemory
[ 2] java.nio.DirectByteBuffer.<init>
[ 3] java.nio.ByteBuffer.allocateDirect
[ 4] DBB.main
[ 5] jdk.internal.reflect.NativeMethodAccessorImpl.invoke0
[ 6] jdk.internal.reflect.NativeMethodAccessorImpl.invoke
[ 7] jdk.internal.reflect.DelegatingMethodAccessorImpl.invoke
[ 8] java.lang.reflect.Method.invoke
[ 9] com.sun.tools.javac.launcher.Main.execute
[10] com.sun.tools.javac.launcher.Main.run
[11] com.sun.tools.javac.launcher.Main.mainBy default, the VM limits the total size or capacity of direct byte buffers to
somewhat the size of the heap.
This can be tuned via -XX:MaxDirectMemorySize. The 4 Full GC cycles indicate
for 20 allocateDirect() and 4 remaining, this means after 4 successful create the 5th allocateDirect
will require a System.gc(), this suggests a max memory limit in this range [419430400;524288000[,
and indeed the reported size of Java Heap section is 522190848 (509952 KiB).
Track memory mapped file with NMT
Using NMT baseline and summary.diff modes, is it possible to
track the memory mapped file usage? Let’s try out.
MappedByteBuffer and NMTpackage sandbox;
import java.nio.channels.FileChannel;
import java.nio.file.*;
public class MappedFiles {
public static void main(String[] args) throws Exception {
System.out.printf("nmt baseline: %n");
new ProcessBuilder("jcmd", Long.toString(ProcessHandle.current().pid()), "VM.native_memory", "baseline")
.start()
.waitFor();
Path src = Paths.get("/usr/lib/jvm/java-11-amazon-corretto/lib/src.zip"); (1)
try (var fileChannel = (FileChannel) Files.newByteChannel(src, StandardOpenOption.READ)) {
var mappedByteBuffer = fileChannel.map(
FileChannel.MapMode.READ_ONLY,
0, (2)
fileChannel.size()); (2)
mappedByteBuffer.load(); (3)
System.out.printf("nmt summary.diff: %n");
new ProcessBuilder("jcmd", Long.toString(ProcessHandle.current().pid()), "VM.native_memory", "summary.diff")
.redirectOutput(ProcessBuilder.Redirect.INHERIT)
.redirectError(ProcessBuilder.Redirect.INHERIT)
.start()
.waitFor();
}
}
}| 1 | Opens a binary file about 50 MiB in size. |
| 2 | Range of the memory mapping starts at 0, up to the total file size. |
| 3 | The load method will actually instruct the OS to load the range defined above
in resident memory. |
Let’s look at what NMT reports.
$ env -u JDK_JAVA_OPTIONS java -XX:NativeMemoryTracking=summary MappedFiles.java
nmt baseline:
nmt summary.diff:
1760:
Native Memory Tracking:
Total: reserved=1929764KB -1028KB, committed=127588KB -44KB
- Java Heap (reserved=509952KB, committed=32768KB)
(mmap: reserved=509952KB, committed=32768KB)
- Class (reserved=1065377KB +1KB, committed=16929KB +1KB)
(classes #2650 +17)
( instance classes #2378 +15, array classes #272 +2)
(malloc=417KB +1KB #5031 +35)
(mmap: reserved=1064960KB, committed=16512KB)
( Metadata: )
( reserved=16384KB, committed=14592KB)
( used=14167KB +34KB)
( free=425KB -34KB)
( waste=0KB =0.00%)
( Class space:)
( reserved=1048576KB, committed=1920KB)
( used=1720KB +9KB)
( free=200KB -9KB)
( waste=0KB =0.00%)
- Thread (reserved=19723KB -1032KB, committed=1027KB -48KB)
(thread #20 -1)
(stack: reserved=19632KB -1028KB, committed=936KB -44KB)
(malloc=69KB -4KB #122 -6)
(arena=22KB #38 -1)
- Code (reserved=247935KB +1KB, committed=7795KB +1KB)
(malloc=247KB +1KB #1692 +9)
(mmap: reserved=247688KB, committed=7548KB)
- GC (reserved=60330KB, committed=42622KB)
(malloc=8570KB #1516 +1)
(mmap: reserved=51760KB, committed=34052KB)
- Compiler (reserved=154KB -1KB, committed=154KB -1KB)
(malloc=21KB #138 -6)
(arena=133KB -1 #5 -1)
- Internal (reserved=579KB, committed=579KB)
(malloc=547KB #1040 -1)
(mmap: reserved=32KB, committed=32KB)
- Other (reserved=10KB, committed=10KB)
(malloc=10KB #2)
- Symbol (reserved=4386KB, committed=4386KB)
(malloc=3163KB #28643 +18)
(arena=1223KB #1)
- Native Memory Tracking (reserved=650KB +2KB, committed=650KB +2KB)
(malloc=7KB +1KB #94 +18)
(tracking overhead=643KB +1KB)
- Arena Chunk (reserved=20529KB +1KB, committed=20529KB +1KB)
(malloc=20529KB +1KB)
- Logging (reserved=4KB, committed=4KB)
(malloc=4KB #191)
- Arguments (reserved=18KB, committed=18KB)
(malloc=18KB #492)
- Module (reserved=60KB, committed=60KB)
(malloc=60KB #1041)
- Synchronizer (reserved=48KB, committed=48KB)
(malloc=48KB #404 -2)
- Safepoint (reserved=8KB, committed=8KB)
(mmap: reserved=8KB, committed=8KB)Nothing.
We’ll see in a later section how to see how much memory mapped files can account in the resident memory.
As a side note before switching to OS tooling, the memory segment used for the memory mapping is not freed until the next GC cycle.
Inspecting memory mappings
It’s easy to get the RSS of a process, to understand if the committed
heap actually resides on physical memory you need to use pmap or inspect
/proc/{pid}/maps or /proc/{pid}/smaps.
The pmap binary is part of the procps
utilities, that contains other tools like: ps, pgrep, watch or vmstat.
It’s likely that no additional installation is required which is great as
a container filesystem should be read-only for security reasons, if it isn’t
there, one could still look at the /proc filesystem.
You have to notice one of the first memory zones is quite big and about the size of the committed heap as shown in NMT.
To select the file mappings we can filter on the access permissions:
-
r-: readable memory mapping -
w: writable memory mapping -
x: executable memory mapping -
sorp: shared memory mapping or private mapping./proc/<pid>/maps
-
R: if set, the map has no swap space reserved (MAP_NORESERVEflag ofmmap). This means that we can get a segmentation fault by accessing that memory if it has not already been mapped to physical memory, and if the system is out of physical memory.
There’s also the value of the inode column, if it’s greater than 0 then
it means the address range is backed by a file, if it’s 0 it’s a memory
allocation that the application has requested.
There are three kinds of memory segments we can easily guess in the memory
mapping reported by pmap because we know their size, it’s the Java heap,
and the threads.
Some other type of allocations can be figured out but that’s for another post.
The remaining address ranges are too difficult to guess for two reasons,
they usually have unpredictable allocation behavior, and it
also depends on the malloc implementation details, (like the
arenas in Glibc),
and on the number malloc calls for a single component.
On a pod running in production let’s have a quick look on the very first mappings.
It’s easier to spot with pmap -X (capital X).
pmap -x {pid}$ pmap -x $(pidof java) | head -n 20
7: /usr/bin/java -Dfile.encoding=UTF-8 -Duser.timezone=UTC -Djava.security.egd=file:/dev/./urandom -Djava.awt.headless=true -XX:NativeMemoryTracking=summary -jar /app/boot.jar
Address Kbytes RSS Dirty Mode Mapping
0000000740000000 3163648 3163648 3163648 rw--- [ anon ] (1)
0000000801180000 1030656 0 0 ----- [ anon ]
000055bac4461000 4 4 0 r-x-- java
000055bac4662000 4 4 4 r---- java
000055bac4663000 4 4 4 rw--- java
000055bac569c000 455704 438268 438268 rw--- [ anon ] (2)
00007ff9b91e7000 16 0 0 ----- [ anon ]
00007ff9b91eb000 1012 24 24 rw--- [ anon ]
00007ff9b92e8000 16 0 0 ----- [ anon ] (3)
00007ff9b92ec000 1012 92 92 rw--- [ anon ] (4)
00007ff9b93e9000 16 0 0 ----- [ anon ]
00007ff9b93ed000 1012 88 88 rw--- [ anon ]
00007ff9b94ea000 16 0 0 ----- [ anon ]
00007ff9b94ee000 1012 24 24 rw--- [ anon ]
00007ff9b95eb000 16 0 0 ----- [ anon ]
00007ff9b95ef000 1012 28 28 rw--- [ anon ]
00007ff9b96ec000 16 0 0 ----- [ anon ]
00007ff9b96f0000 1012 24 24 rw--- [ anon ]| 1 | native heap memory heap |
| 2 | java heap |
| 3 | a thread guard pages |
| 4 | a thread stack |
pmap -X {pid}$ pmap -X $(pidof java) | head -n 20
7: /usr/bin/java -Dfile.encoding=UTF-8 -Duser.timezone=UTC -Djava.security.egd=file:/dev/./urandom -Djava.awt.headless=true -XX:NativeMemoryTracking=summary -javaagent:/newrelic-agent.jar -javaagent:/dd-java-agent.jar -jar /edge-api-boot.jar --spring.config.additional-location=/etc/edge-api/config.yaml --server.port=8080
Address Perm Offset Device Inode Size Rss Pss Referenced Anonymous LazyFree ShmemPmdMapped Shared_Hugetlb Private_Hugetlb Swap SwapPss Locked THPeligible Mapping
740000000 rw-p 00000000 00:00 0 3163648 3163648 3163648 3163648 3163648 0 0 0 0 0 0 0 0 (1)
801180000 ---p 00000000 00:00 0 1030656 0 0 0 0 0 0 0 0 0 0 0 0
55bac4461000 r-xp 00000000 08:01 5623642 4 4 4 4 0 0 0 0 0 0 0 0 0 java
55bac4662000 r--p 00001000 08:01 5623642 4 4 4 4 4 0 0 0 0 0 0 0 0 java
55bac4663000 rw-p 00002000 08:01 5623642 4 4 4 4 4 0 0 0 0 0 0 0 0 java
55bac569c000 rw-p 00000000 00:00 0 455704 438268 438268 438268 438268 0 0 0 0 0 0 0 0 [heap] (2)
7ff9b91e7000 ---p 00000000 00:00 0 16 0 0 0 0 0 0 0 0 0 0 0 0
7ff9b91eb000 rw-p 00000000 00:00 0 1012 28 28 28 28 0 0 0 0 0 0 0 0
7ff9b92e8000 ---p 00000000 00:00 0 16 0 0 0 0 0 0 0 0 0 0 0 0 (3)
7ff9b92ec000 rw-p 00000000 00:00 0 1012 92 92 92 92 0 0 0 0 0 0 0 0 (4)
7ff9b93e9000 ---p 00000000 00:00 0 16 0 0 0 0 0 0 0 0 0 0 0 0
7ff9b93ed000 rw-p 00000000 00:00 0 1012 88 88 88 88 0 0 0 0 0 0 0 0
7ff9b94ea000 ---p 00000000 00:00 0 16 0 0 0 0 0 0 0 0 0 0 0 0
7ff9b94ee000 rw-p 00000000 00:00 0 1012 24 24 24 24 0 0 0 0 0 0 0 0
7ff9b95eb000 ---p 00000000 00:00 0 16 0 0 0 0 0 0 0 0 0 0 0 0
7ff9b95ef000 rw-p 00000000 00:00 0 1012 28 28 28 28 0 0 0 0 0 0 0 0
7ff9b96ec000 ---p 00000000 00:00 0 16 0 0 0 0 0 0 0 0 0 0 0 0
7ff9b96f0000 rw-p 00000000 00:00 0 1012 24 24 24 24 0 0 0 0 0 0 0 0| 1 | native heap memory heap |
| 2 | java heap |
| 3 | a thread guard pages |
| 4 | a thread stack |
/proc/{pid}/maps$ cat /proc/$(pidof java)/maps | head -n 20
740000000-801180000 rw-p 00000000 00:00 0 (1)
801180000-840000000 ---p 00000000 00:00 0
55bac4461000-55bac4462000 r-xp 00000000 08:01 5623642 /usr/lib/jvm/java-11-amazon-corretto/bin/java
55bac4662000-55bac4663000 r--p 00001000 08:01 5623642 /usr/lib/jvm/java-11-amazon-corretto/bin/java
55bac4663000-55bac4664000 rw-p 00002000 08:01 5623642 /usr/lib/jvm/java-11-amazon-corretto/bin/java
55bac569c000-55bae13a2000 rw-p 00000000 00:00 0 [heap] (2)
7ff9b91e7000-7ff9b91eb000 ---p 00000000 00:00 0
7ff9b91eb000-7ff9b92e8000 rw-p 00000000 00:00 0
7ff9b92e8000-7ff9b92ec000 ---p 00000000 00:00 0 (3)
7ff9b92ec000-7ff9b93e9000 rw-p 00000000 00:00 0 (4)
7ff9b93e9000-7ff9b93ed000 ---p 00000000 00:00 0
7ff9b93ed000-7ff9b94ea000 rw-p 00000000 00:00 0
7ff9b94ea000-7ff9b94ee000 ---p 00000000 00:00 0
7ff9b94ee000-7ff9b95eb000 rw-p 00000000 00:00 0
7ff9b95eb000-7ff9b95ef000 ---p 00000000 00:00 0
7ff9b95ef000-7ff9b96ec000 rw-p 00000000 00:00 0
7ff9b96ec000-7ff9b96f0000 ---p 00000000 00:00 0
7ff9b96f0000-7ff9b97ed000 rw-p 00000000 00:00 0
7ff9b97ed000-7ff9b97f1000 ---p 00000000 00:00 0
7ff9b97f1000-7ff9b99ee000 rw-p 00000000 00:00 0| 1 | native heap memory heap |
| 2 | java heap |
| 3 | a thread guard pages |
| 4 | a thread stack |
The first thing to natice is that pmap choses to display the start address,
and the size of the mapping in another column, while the maps file is using
address ranges. As you might have guessed, the sum of the size of these mapping
is the value one can see in the vsz column of ps.
-
740000000-801180000(3163648 KiB), around3 GiBin a simple mapping, this looks like the size of the heap, subtracting the addressed gives this number3 239 575 552, which very close to the VM actual flag for the heap-XX:MaxHeapSize=3221225472, the JVM must map additional space. We also note that the RSS on this mapping is equal to the size, this means that either this flag-XX:+AlwaysPreTouchis active, or that all pages in the heap have been touched once, for this app this is the former case.This single address range, also indicates that the minimum and the maximum value of the heap is the same
Xmx=Xms. If they weren’t we would have seen two adjacent segment with different permissions (rw-pthen---p), the JVM can grow the read-and-write segment of the Java Heap.Just under this mapping there’s another one
801180000-840000000(1030656 KiB), around1 GiB, one could think it’s the metaspace, but it isn’t. Looking at the other columns, the mode or permissions or the RSS, we see respectively---pand0, this means this memory segment is reserved but it is not writeable.Finding the metaspace cannot be done this way.
-
55bac569c000-55bae13a2000, on the extendedpmapoutput this mapping has a nameheap, this one is the native java heap of the Java process. One can notice the next mapping address (7ff9b91e7000) is not adjacent, this allows the native heap to grow if necessary. The virtual size of this mapping is~445 MiBand the active pages amounts to428 MiB. -
Then there’s a lot of mapping with this pattern, first
16 KiBwith no permission (---p) immediately followed by a1012 KiBsegment with read and write permissions (rw-p), those are the Java threads, by default the virtual size the of the thread stack size is1 MiB, theThreadStackSizeflag control this maximum stack size.The
16 KiBare the thread guard pages, the number of pages (4 KiB) is controlled byStackReservedPages,StackYellowPagesandStackRedPageswhose defaults are respectively1,2, and1. They are used when a stack overflow error happens, normally the guard pages cannot be written to, their permission will change in order to handle the error ; read this explanation from Andrei Pangin to learn more on this topic.For the keen observer the virtual size of these two memory segment is
1028 KiB, a bit more than1 MiB, I’ve learned a few months ago that glibc, and other allocators apparently adds one page to the allocated stack size, if the segment size is a multiple of 64K.This is to prevent aliasing on the CPU cache lines
A 64K-aliasing conflict occurs when a virtual address memory references a cache line that is modulo 64K bytes apart from another cache line that already resides in the first level cache. Only one cache line with a virtual address modulo 64K bytes can reside in the first level cache at the same time.
For example, accessing a byte at virtual addresses 0x10000 and 0x3000F would cause a 64K aliasing conflict. This is because the virtual addresses for the two bytes reside on cache lines that are modulo 64K bytes apart.
In other words one can see an additional
4 KiB(a page), for stack size like512 KiB,256 KiB,128 KiB,64 KiB.That being said, if pages in the mapping are not touched, they do not account as resident memory. This
55bac569c000-55bae13a2000mapping tells the stack was at most92 KiB. Anyway with more threads there will be naturally more consumed resident memory.
The other JVM components are harder to identify due to the way they are allocated.
That being said pmap reveals file-backed memory mapping, these consumes pages too.
Inspecting memory mapped files
The NativeMemoryTracking output showed memory usage of the JVM, but it didn’t report
MappedByteBuffers, those are the files that are memory mapped to the virtual memory
of a process as explained above via the native mmap call.
There are two ways to read a file using a file descriptor, generally it happens when
opening a FileInputStream,
or using memory mapping via a
FileChannel.
When a file is memory mapped, the range of the content is divided by pages too, and when accessed they are copied in RAM by the OS, these are accounted in RSS. For this reason they may deserve some attention if RSS usage is high but the app memory alone is not enough.
The Mapping column on the of pmap -x $(pgrep java) can be parsed to identify
file mappings, but this is brittle and unnecessary, one can simply look at
the output of pmap -X $(pgrep java) (notice the big X) or even at the
/proc/$(pidof java)/maps content looking for a non-zero value of the inode
column meaning this mapping is file backed.
Using the output of pmap -X $(pgrep java) and selecting the matching lines
with awk this is easy:
$ pmap -X $(pidof java) \
| head -n -2 \ (4)
| awk '{ if (NR <= 2 || $5 >0 ) \ (1)
printf "%12s %8s %8s %4s %s\n", \ (2)
$1, \
$6, \
$7, \
$2, \
$19 }' (2)
7: -Djava.awt.headless=true -XX:NativeMemoryTracking=summary /usr/bin/java
Address Size Rss Perm Mapping (3)
561ddb94a000 4 4 r-xp java
561ddbb4b000 4 4 r--p java
561ddbb4c000 4 4 rw-p java
7f355521f000 4 4 r--s instrumentation9549273990865322165.jar
7f355964d000 4 4 r--s instrumentation14393425676176063484.jar
7f3559e50000 1160 1160 r--s dd-java-agent.jar
7f355a372000 256 192 r-xp libsunec.so
7f355a3b2000 2048 0 ---p libsunec.so
7f355a5b2000 20 20 r--p libsunec.so
7f355a5b7000 8 8 rw-p libsunec.so
7f355a7b9000 16 16 r--p libresolv-2.28.so
7f355a7bd000 52 52 r-xp libresolv-2.28.so
7f355a7ca000 16 16 r--p libresolv-2.28.so
7f355a7ce000 4 0 ---p libresolv-2.28.so
7f355a7cf000 4 4 r--p libresolv-2.28.so
7f355a7d0000 4 4 rw-p libresolv-2.28.so
7f355a7d3000 4 4 r--p libnss_dns-2.28.so
7f355a7d4000 16 16 r-xp libnss_dns-2.28.so
7f355a7d8000 4 0 r--p libnss_dns-2.28.so
7f355a7d9000 4 4 r--p libnss_dns-2.28.so
7f355a7da000 4 4 rw-p libnss_dns-2.28.so
7f355a7dd000 4 4 r--s instrumentation13129117816180832587.jar
7f355a7de000 8 8 r-xp libextnet.so
7f355a7e0000 2044 0 ---p libextnet.so
7f355a9df000 4 4 r--p libextnet.so
7f355b9e9000 4 4 r--s newrelic-bootstrap1151474907525430822.jar
7f355bfea000 24 24 r-xp libmanagement_ext.so
7f355bff0000 2044 0 ---p libmanagement_ext.so
7f355c1ef000 4 4 r--p libmanagement_ext.so
7f355c1f0000 4 4 rw-p libmanagement_ext.so
7f355c1f1000 16 16 r-xp libmanagement.so
7f355c1f5000 2048 0 ---p libmanagement.so
7f355c3f5000 4 4 r--p libmanagement.so
7f355c5f7000 8 8 r--s newrelic-weaver-api14962018995408739070.jar
7f355c5f9000 12 12 r--s newrelic-api8237374132620194936.jar
7f355c5fc000 4 4 r--s newrelic-opentracing-bridge6621669571490510163.jar
7f355c5fd000 16 16 r--s agent-bridge7978421659510986627.jar
7f355c601000 88 88 r-xp libnet.so
7f355c617000 2048 0 ---p libnet.so
7f355c817000 4 4 r--p libnet.so
7f355c818000 4 4 rw-p libnet.so
7f355c819000 64 64 r-xp libnio.so
7f355c829000 2048 0 ---p libnio.so
7f355ca29000 4 4 r--p libnio.so
7f355ca2a000 4 4 rw-p libnio.so
7f355cf30000 200 128 r--p LC_CTYPE
7f355cf62000 4 4 r--p LC_NUMERIC
7f355cf63000 4 4 r--p LC_TIME
7f355cf64000 1484 156 r--p LC_COLLATE
7f355d0d7000 4 4 r--p LC_MONETARY
7f355d0d8000 4 4 r--p SYS_LC_MESSAGES
7f355d0d9000 4 4 r--p LC_PAPER
7f355d0da000 4 4 r--p LC_NAME
7f355d0db000 28 28 r--s gconv-modules.cache
7f357663b000 138232 30036 r--s modules
7f357ed39000 104 92 r-xp libzip.so
7f357ed53000 2044 0 ---p libzip.so
7f357ef52000 4 4 r--p libzip.so
7f357ef5c000 12 12 r--p libnss_files-2.28.so
7f357ef5f000 28 28 r-xp libnss_files-2.28.so
7f357ef66000 8 8 r--p libnss_files-2.28.so
7f357ef68000 4 0 ---p libnss_files-2.28.so
7f357ef69000 4 4 r--p libnss_files-2.28.so
7f357ef6a000 4 4 rw-p libnss_files-2.28.so
7f357ef71000 4 4 r--p LC_ADDRESS
7f357ef72000 4 4 r--p LC_TELEPHONE
7f357ef73000 4 4 r--p LC_MEASUREMENT
7f357ef74000 40 40 r-xp libinstrument.so
7f357ef7e000 2044 0 ---p libinstrument.so
7f357f17d000 4 4 r--p libinstrument.so
7f357f17e000 4 4 rw-p libinstrument.so
7f357f17f000 108 64 r-xp libjimage.so
7f357f19a000 2048 0 ---p libjimage.so
7f357f39a000 8 8 r--p libjimage.so
7f357f39c000 4 4 rw-p libjimage.so
7f357f39d000 164 164 r-xp libjava.so
7f357f3c6000 2048 0 ---p libjava.so
7f357f5c6000 4 4 r--p libjava.so
7f357f5c7000 4 4 rw-p libjava.so
7f357f5c9000 68 68 r-xp libverify.so
7f357f5da000 2044 0 ---p libverify.so
7f357f7d9000 8 8 r--p libverify.so
7f357f7dc000 8 8 r--p librt-2.28.so
7f357f7de000 16 16 r-xp librt-2.28.so
7f357f7e2000 8 0 r--p librt-2.28.so
7f357f7e4000 4 4 r--p librt-2.28.so
7f357f7e5000 4 4 rw-p librt-2.28.so
7f357f8e7000 17680 15012 r-xp libjvm.so
7f3580a2b000 2044 0 ---p libjvm.so
7f3580c2a000 764 764 r--p libjvm.so
7f3580ce9000 228 228 rw-p libjvm.so
7f3580d7d000 12 12 r--p libgcc_s.so.1
7f3580d80000 68 64 r-xp libgcc_s.so.1
7f3580d91000 12 12 r--p libgcc_s.so.1
7f3580d94000 4 0 ---p libgcc_s.so.1
7f3580d95000 4 4 r--p libgcc_s.so.1
7f3580d96000 4 4 rw-p libgcc_s.so.1
7f3580d97000 52 52 r--p libm-2.28.so
7f3580da4000 636 368 r-xp libm-2.28.so
7f3580e43000 852 128 r--p libm-2.28.so
7f3580f18000 4 4 r--p libm-2.28.so
7f3580f19000 4 4 rw-p libm-2.28.so
7f3580f1a000 548 548 r--p libstdc++.so.6.0.25
7f3580fa3000 688 192 r-xp libstdc++.so.6.0.25
7f358104f000 248 64 r--p libstdc++.so.6.0.25
7f358108d000 4 0 ---p libstdc++.so.6.0.25
7f358108e000 40 40 r--p libstdc++.so.6.0.25
7f3581098000 8 8 rw-p libstdc++.so.6.0.25
7f35810a0000 136 136 r--p libc-2.28.so
7f35810c2000 1312 1208 r-xp libc-2.28.so
7f358120a000 304 152 r--p libc-2.28.so
7f3581256000 4 0 ---p libc-2.28.so
7f3581257000 16 16 r--p libc-2.28.so
7f358125b000 8 8 rw-p libc-2.28.so
7f3581261000 4 4 r--p libdl-2.28.so
7f3581262000 4 4 r-xp libdl-2.28.so
7f3581263000 4 4 r--p libdl-2.28.so
7f3581264000 4 4 r--p libdl-2.28.so
7f3581265000 4 4 rw-p libdl-2.28.so
7f3581266000 100 100 r-xp libjli.so
7f358127f000 2048 0 ---p libjli.so
7f358147f000 4 4 r--p libjli.so
7f3581480000 4 4 rw-p libjli.so
7f3581481000 24 24 r--p libpthread-2.28.so
7f3581487000 60 60 r-xp libpthread-2.28.so
7f3581496000 24 0 r--p libpthread-2.28.so
7f358149c000 4 4 r--p libpthread-2.28.so
7f358149d000 4 4 rw-p libpthread-2.28.so
7f35814a2000 4 4 r--p LC_IDENTIFICATION
7f3581878000 4 4 r--p ld-2.28.so
7f3581879000 120 120 r-xp ld-2.28.so
7f3581897000 32 32 r--p ld-2.28.so
7f358189f000 4 4 r--p ld-2.28.so
7f35818a0000 4 4 rw-p ld-2.28.so| 1 | Filter lines that have an Inode value over 0 and only from the 3rd line (included). |
| 2 | Print only some columns, `pmap -X {pid}’s output is verbose. |
| 3 | The columns are select to match the output of pmap -x, Size column is in KiB. |
| 4 | The last two lines are filtered out; the actual
sums of the size and rss columns of the selected rows are respectively
195336 KiB and 52316 KiB. |
What may catch the eye is the multiple mapping for native libraries like libjvm.so.
The reason for these different memory mapping is how dynamic libraries are loaded
(with dlopen, e.g. here os::Linux::dlopen_helper).
I didn’t have any system courses, but from what I believe I know dlopen
will make multiple memory mapping with different objectives and permissions:
-
r-xpmeans an executable segment of the library, probably the native execution stack of the native library -
r--pmeans readable memory of the library, I believe it is the library constants or symbols -
rw-pmeans writable memory, I think its purpose is for the main process to set global variables of the library -
---pis a no permission segment, I’m not sure about this one, but it’s location (between executable and writable segments) makes me think it’s about buffer overflow prevention
Simple C code example that performs a dlopen
The program below will simply load the shared dynamic library libjvm.so,
and won’t even interact with it. The result shows the 4 mappings
with the different modes.
#include <stdio.h>
#include <unistd.h>
#include <dlfcn.h>
int main (int argc, char *argv[])
{
pid_t pid = getpid();
printf("pid: %d\n", pid);
void* libjava_handle=dlopen("lib/server/libjvm.so", RTLD_LAZY);
if (!libjava_handle) {
fputs (dlerror(), stderr);
exit(1);
}
char buffer[50];
sprintf(buffer, "pmap -X %d", pid);
printf("Executing: '%s'\n", buffer);
system(buffer);
return 0;
}$ env LD_LIBRARY_PATH=$JAVA_HOME/lib/server ./test-dlopen
pid: 608
Executing: 'pmap -x -p 608'
608: ./test-dlopen
Address Kbytes RSS Dirty Mode Mapping
0000000000400000 4 4 0 r-x-- /src/build/exe/dlopen/test-dlopen
0000000000600000 4 4 4 r---- /src/build/exe/dlopen/test-dlopen
0000000000601000 4 4 4 rw--- /src/build/exe/dlopen/test-dlopen
0000000001ba0000 132 16 16 rw--- [ anon ]
00007f3374f11000 92 92 0 r-x-- /usr/lib64/libpthread-2.17.so
00007f3374f28000 2044 0 0 ----- /usr/lib64/libpthread-2.17.so
00007f3375127000 4 4 4 r---- /usr/lib64/libpthread-2.17.so
00007f3375128000 4 4 4 rw--- /usr/lib64/libpthread-2.17.so
00007f3375129000 16 4 4 rw--- [ anon ]
00007f337512d000 18516 5324 0 r-x-- /usr/lib/jvm/java-11-openjdk-11.0.9.11-0.el7_9.x86_64/lib/server/libjvm.so (1)
00007f3376342000 2048 0 0 ----- /usr/lib/jvm/java-11-openjdk-11.0.9.11-0.el7_9.x86_64/lib/server/libjvm.so (2)
00007f3376542000 836 836 836 r---- /usr/lib/jvm/java-11-openjdk-11.0.9.11-0.el7_9.x86_64/lib/server/libjvm.so (3)
00007f3376613000 236 216 216 rw--- /usr/lib/jvm/java-11-openjdk-11.0.9.11-0.el7_9.x86_64/lib/server/libjvm.so (4)
00007f337664e000 360 240 240 rw--- [ anon ]
00007f33766a8000 1808 1184 0 r-x-- /usr/lib64/libc-2.17.so
00007f337686c000 2044 0 0 ----- /usr/lib64/libc-2.17.so
00007f3376a6b000 16 16 16 r---- /usr/lib64/libc-2.17.so
00007f3376a6f000 8 8 8 rw--- /usr/lib64/libc-2.17.so
00007f3376a71000 20 12 12 rw--- [ anon ]
00007f3376a76000 84 64 0 r-x-- /usr/lib64/libgcc_s-4.8.5-20150702.so.1
00007f3376a8b000 2044 0 0 ----- /usr/lib64/libgcc_s-4.8.5-20150702.so.1
00007f3376c8a000 4 4 4 r---- /usr/lib64/libgcc_s-4.8.5-20150702.so.1
00007f3376c8b000 4 4 4 rw--- /usr/lib64/libgcc_s-4.8.5-20150702.so.1
00007f3376c8c000 1028 208 0 r-x-- /usr/lib64/libm-2.17.so
00007f3376d8d000 2044 0 0 ----- /usr/lib64/libm-2.17.so
00007f3376f8c000 4 4 4 r---- /usr/lib64/libm-2.17.so
00007f3376f8d000 4 4 4 rw--- /usr/lib64/libm-2.17.so
00007f3376f8e000 932 520 0 r-x-- /usr/lib64/libstdc++.so.6.0.19
00007f3377077000 2048 0 0 ----- /usr/lib64/libstdc++.so.6.0.19
00007f3377277000 32 32 32 r---- /usr/lib64/libstdc++.so.6.0.19
00007f337727f000 8 8 8 rw--- /usr/lib64/libstdc++.so.6.0.19
00007f3377281000 84 12 12 rw--- [ anon ]
00007f3377296000 8 8 0 r-x-- /usr/lib64/libdl-2.17.so
00007f3377298000 2048 0 0 ----- /usr/lib64/libdl-2.17.so
00007f3377498000 4 4 4 r---- /usr/lib64/libdl-2.17.so
00007f3377499000 4 4 4 rw--- /usr/lib64/libdl-2.17.so
00007f337749a000 136 136 0 r-x-- /usr/lib64/ld-2.17.so
00007f33776af000 24 24 24 rw--- [ anon ]
00007f33776b9000 8 8 8 rw--- [ anon ]
00007f33776bb000 4 4 4 r---- /usr/lib64/ld-2.17.so
00007f33776bc000 4 4 4 rw--- /usr/lib64/ld-2.17.so
00007f33776bd000 4 4 4 rw--- [ anon ]
00007ffc83b1d000 132 12 12 rw--- [ stack ]
00007ffc83b41000 12 0 0 r---- [ anon ]
00007ffc83b44000 4 4 0 r-x-- [ anon ]
ffffffffff600000 4 0 0 r-x-- [ anon ]
---------------- ------- ------- -------
total kB 38912 9040 1496In the above snippet the mapped files represents 195.3 MiB of the address space
of which 52.3 MiB are actually resident. This app is definitely OK. Some
application’s workload require to handle a lot of files suggesting raising the limit
may be the right thing. I’ve seen in the past FileChannel unreleased mappings,
leading to increasing memory consumption that weren’t easily identifiable in the Java heap
(unless you had to perform a heap dump and knew what to look at).
Inspecting the other segments
Going beyond what has been mentioned is a tad more intricate due
to how native code is performing allocations.
Even identifying direct ByteBuffer is almost impossible, the little program below
allocates 16 MiB segments and print the address of these memory segments, as well
as the current process mapping.
System.out.printf("max: %d%n", Runtime.getRuntime().maxMemory());
new ProcessBuilder("pmap", "-x", Long.toString(ProcessHandle.current().pid()))
.redirectOutput(Redirect.INHERIT)
.start()
.waitFor();
var address = Buffer.class.getDeclaredField("address");
address.setAccessible(true);
System.out.printf("native heap (pmap shows [heap] mapping");
for (var i = 0; i < 30; i++) {
var byteBuffer = ByteBuffer.allocateDirect(16 * 1024 * 1024)
.putInt(0, 0x01);
System.out.printf("%s%n", Long.toHexString(address.getLong(byteBuffer)));
}
new ProcessBuilder("pmap", "-x", Long.toString(ProcessHandle.current().pid()))
.redirectOutput(Redirect.INHERIT)
.start()
.waitFor();The mapping output after the buffers have been malloced shows
that the direct ByteBuffers do not have their own segment, they are
part of a bigger area.
|
before
after
|
Here I can say those are likely our ByteBuffers, because I had the opportunity
to diff the pmap output around code that specifically created the new direct
buffers. Also, I know that direct ByteBuffers are zeroed, i.e. pages
are touched/dirty, i.e. direct byte buffers immediately count toward the RSS.
In a real application it’s impossible to identify them with certainty without the address. The possible criteria would be RSS and size are the same for the segment, permissions are read write and of course it’s anonymous mapping, but any other allocation pattern or usage could meet these criteria.
Finally, if pmap is run with -X it’s likely you’ll notice segments named
vsyscall vdso, these are
mechanisms that can accelerate some system calls.
vvar is used to exchange Kernel data without requiring a system call.
How many pages are used ?
In fact, ps uses the proc file system to obtain its information.
While not immediately useful, it’s interesting that the displayed RSS value
by ps is in fact the number of page times the page size. (I suppose the
equation is a tad more complex than a single multiplication when huge pages
are involved).
For example in the procfs documentation
(the latest, as in latest kernel, documentation is
there) gives the
description of the statm object.
Table 1-3: Contents of the statm files (as of 2.6.8-rc3) .............................................................................. Field Content size total program size (pages) (same as VmSize in status) resident size of memory portions (pages) (same as VmRSS in status) shared number of pages that are shared (i.e. backed by a file, same as RssFile+RssShmem in status) trs number of pages that are 'code' (not including libs; broken, includes data segment) lrs number of pages of library (always 0 on 2.6) drs number of pages of data/stack (including libs; broken, includes library text) dt number of dirty pages (always 0 on 2.6)
ps and /proc/{pid}/statm$ ps -o rss,vsz,command $(pidof java)
RSS VSZ COMMAND
4346704 6507368 /usr/bin/java -Dfile.encoding=UTF-8 -Duser.timezone=UTC -Djava.security.egd=file:/dev/./urandom -Djava
$ cat /proc/$(pidof java)/statm | tr ' ' '\n'
1626842 (1)
1086676 (2)
12638 (3)
1
0
1283103
0| 1 | Total size in pages of the addressing space, in bytes : 6507368 KiB |
| 2 | Resident memory in pages, in bytes : 4346704 KiB |
| 3 | pages backed by a file plus shared memory |
Given the page size of 4 KiB, the following numbers comes naturally :
-
vsz =
1626842 * 4 = 6507368 -
rss =
1086676 * 4 = 4346704
For example lets say there is a Kubernetes memory limit (This limit is in fact
a cgroup memory limit) of 6 GiB (6442450944 Bytes ), a java process
is started with a bigger memory -Xmx16g that the cgroup limit, we can observe
that:
-
a process can over-commit, if Linux is configured to allow this (
/proc/sys/vm/overcommit_memory), this is not an issue as long as -
the memory used by the resident pages do not go over the cgroup limit.
-
The process will be oom-killed if it uses more than
6442450944 / 4 = 1310720pages (of4 KiB).
import java.io.*;
public class SelfPs {
public static void main(String[] args) throws Exception {
var h = new ProcessBuilder("ps",
"--no-header",
"-orss,vsz",
Long.toString(ProcessHandle.current().pid()))
.start();
try(var br = new BufferedReader(new InputStreamReader(h.getInputStream()))) {
System.out.println(br.readLine());
}
}
}$ env -u JDK_JAVA_OPTIONS java -Xms16g -Xmx16g SelfPs.java
143584 18996472 (1) (2)
$ cat /sys/fs/cgroup/memory/memory.limit_in_bytes
6442450944 (3)
$ echo $((18996472 * 1024))
19452387328 (4)| 1 | RSS in KiB |
| 2 | virtual address space in KiB |
| 3 | cgroup limit |
| 4 | virtual address space in bytes |
Another interesting element of /proc/{pid}/statm is that it shows
how many pages the mapped files take.
In the output below, the third line, give the number of pages that
are backed by files.
Having a look at this information may also be useful when sizing the container.
$ cat /proc/$(pidof java)/statm | tr ' ' '\n'
1514761
1009054
11222 (1)
1
0
1164939
0
$ pmap -X $(pidof java) | head -n -2 | awk '{ if (NR > 2 && $5 >0 ) sum += $7 } END { print sum }'
46796 (2)| 1 | Number of pages backed by files or shared memory, so 11222 * 4 = 44888 |
| 2 | Resident set size of memory mapped files in KiB, not including shared pages that are not file backed. |
Paging and the Java heap
Before wrapping this article I’d like to mention an interesting effect of virtual memory, over-commit and Java Heap.
The pages of the Java heap memory segment count if these pages have initialized at least once, during the life of the program, the activity of the program and the GC will increase the number of touched pages, pages that count in the RSS.
For G1GC . New allocation will happen in a GC region called Eden, and more specifically in a sub-segment called TLAB dedicated for the thread that perform the allocation.
-
After some time the GC will kick in and move (or evacuate) the live objects to GC region called Survivor.
-
This cycle will go on until the object is considered old enough to be evacuated to a GC region called Old.
After each evacuation, the regions that previously held the objects,
are cleaned up, and their bits set to 0, but the page are still considered dirty
and count in the RSS. This region will return to a pool of Free regions.
For the evacuation, the live objects can go to existing region if they have some space or if there’s not enough space in the existing regions, G1GC will convert a Free region to either a Survivor or an Old region. If the Free region has been used before then no new pages will get dirty, however if the Free region has never been in use before then this will touch more pages.

This can lead to a situation if the Java heap is large enough, where many never-used-before Free region exists. In this situation it is not obvious to distinguish from metrics what is consuming the memory.
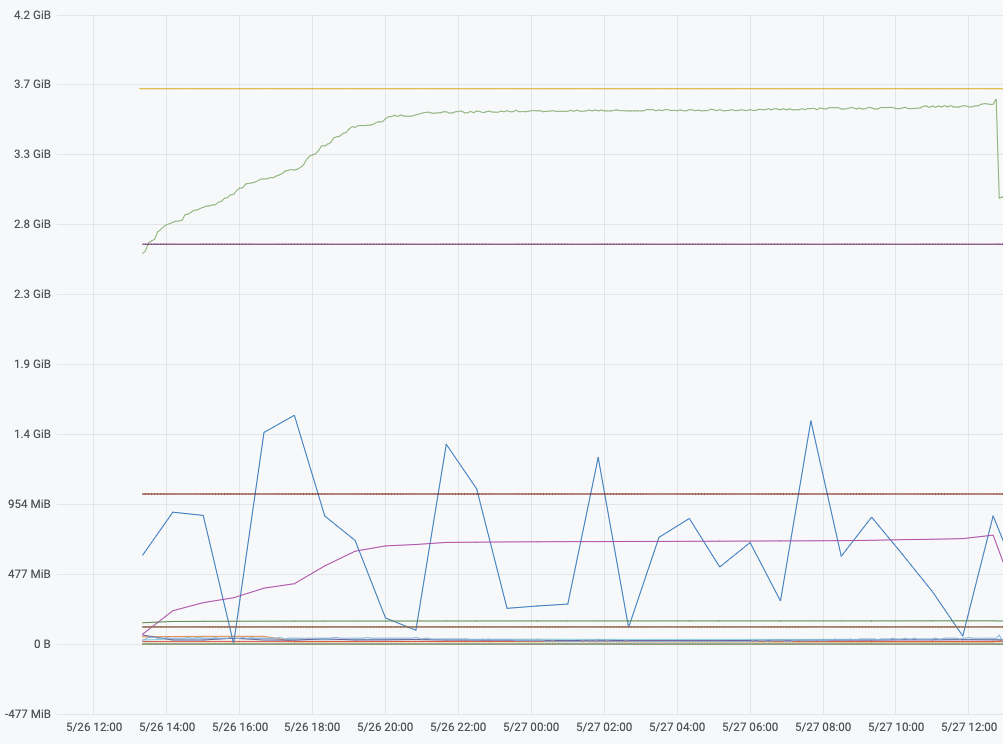
Some people may have heard of the -XX:+AlwaysPreTouch Hotspot option.
This option tells the JVM to
write a zero to every OS memory pages during the JVM startup.
This option has also the effect of avoiding physical memory commit
latencies later at runtime, however this only affects the heap memory zone.
Other JVM component that manage areas like thread stack or metaspace work
differently.
In other words that means parts of the committed memory shown in NMT is not resident and as such RSS counter may not reflect what is seen in the committed memory.
Sizing a cgroup / kubernetes resources.memory.limit
With containerization getting traction it is likely that one has to face a memory related issue. Being equipped with the right tooling and the tool manual is a precious help.
When a container is oomkilled either the application has problem or its configuration is too tight.
Using the gathered information from JVM’s native memory tracking and from memory mapping, is it possible to build a simple equation to estimate the probable maximum memory usage of a process ?
|
We can already suppose there’s every reported components from the JVM, and the mapped files reported by NMT.
Total memory = Heap + GC + Metaspace + Code Cache + Symbol tables
+ Compiler + Other JVM structures + Thread stacks
+ Direct buffers + Mapped files
Above in this writing I noted NMT is not enough to account used memory.
$ jcmd $(pidof java) VM.native_memory \
| grep -P "Total.*committed=" \
| grep -o -P "(?<=committed=)[0-9]+(?=KB)"
3841302 (1)
$ ps --no-header -o rss $(pidof java)
4204512 (2)
$ pmap -X $(pidof java) | head -n -2 | awk '{ if (NR > 2 && $5 >0 ) sum += $7 } END { print sum }'
52668 (3)
$ echo $((4204512 - 3841303 - 52668))
363209 (4)| 1 | Total committed memory reported by NMT |
| 2 | RSS of the JVM process |
| 3 | RSS of the JVM process’s mapped files |
| 4 | The rest of the used memory possibly malloc or mmap performed by native libs, native allocator overhead |
Basically this shows that one must account at least this amount of data when defining the kubernetes limit.
Total memory = Heap + GC + Metaspace + Code Cache + Symbol tables
+ Compiler + Other JVM structures + Thread stacks
+ Direct buffers + Mapped files +
+ Native libraries allocations + Malloc overhead
+ ...
In my experience if the application doe not exhibit leaky behavior but just need
memory limit adjustment. The job is way easier using AlwaysPreTouch, then it’s
easier to track evolution of "off-heap" memory.
Additionally, when sizing the memory limit, it’s really important to think about the OS page cache. Linux uses the unused resident memory to cache pages, usually the one backed by files.
Workloads that access the filesystem for a living, like Cassandra or ElasticSearch will profit of the OS page cache. It’s a good bet to increase the memory limit for this cgroup.
By how much, that depends. I believe page faults is a good indicator. It’s likely that if there’s page faults of the container, it means that the OS don’t have the wanted pages in resident memory and as such the kernel must fetch the backing data, likely on the slower storage device. This is likely something that will negatively affect the workload latencies.
Closing words
A cgroup is a double-edged sword, it creates good conditions to isolate a process. Being isolated, it gets easier to provision the necessary resources in production. Defining these boundaries is however a tedious task, having limits too narrow could increase the chance of the container getting oomkilled or having poor performance, giving a vast room will reduce the ability of Kubernetes to distribute the workload, and it costs more.
In this very long writing, I showed two tools to survey the native
memory of a process. Java ships with a very interesting tracking
mechanism. I found out that inspecting Linux /proc filesystem, with
the help of pmap complement NMT well. Together they help to sort out
memory problems be it a limit should that needs adjustment or something
to fix in the application.
That being said it might be cheaper to look at other solutions, e.g. if the production is running on Kubernetes it would be worth to have a look at auto-scalers provided by the platform.
I think that understanding how a workload use the memory is still a sensible task, to make a better use of the auto-scalers.
The JVM is handling it.
I understand that having to go down that much may look superfluous and almost zealous to when coming from the Java world.
In my opinion, containers changed the deal, the tighter constraints that helped to increase the deployment density, are now backfiring. On a side note those that tried cgroups with CPU limit have likely experienced throttled on applications. Memory wise rediscovering RSS is essential.
Thanks
The above writing tries to piece together elements from a few things I knew, things I grepped in the JDK codebase, blog posts, stack overflow, and things learned from — awesome — people. I hope I didn’t forget someone, if I did or if I’m wrong please reach out.
I’d like to thank Pierre Laporte, Olivier Bourgain, Bastien Lemale, and Yohan Legat for their early help in proof-reading and suggestions. And many thanks to Jean-Philippe Bempel, Mathis Raguin and Juraj Martinka for post-production reviews ;)